

David Bau
@davidbau.bsky.social
Interpretable Deep Networks. http://baulab.info/ @davidbau
When you read the paper, be sure to check out the appendix where @arnab_api discusses how pointer and value data are entangled in filters.
And possible applications of the filter mechanism, like as a zero-shot "lie detector" that can flag incorrect statements in ordinary text.
And possible applications of the filter mechanism, like as a zero-shot "lie detector" that can flag incorrect statements in ordinary text.

November 6, 2025 at 2:00 PM
When you read the paper, be sure to check out the appendix where @arnab_api discusses how pointer and value data are entangled in filters.
And possible applications of the filter mechanism, like as a zero-shot "lie detector" that can flag incorrect statements in ordinary text.
And possible applications of the filter mechanism, like as a zero-shot "lie detector" that can flag incorrect statements in ordinary text.
The neural representations for LLM filter heads are language independent!
If we pick up the representation for a question in French, it will accurately match items expressed in the Thai language.
If we pick up the representation for a question in French, it will accurately match items expressed in the Thai language.

November 6, 2025 at 2:00 PM
The neural representations for LLM filter heads are language independent!
If we pick up the representation for a question in French, it will accurately match items expressed in the Thai language.
If we pick up the representation for a question in French, it will accurately match items expressed in the Thai language.
How embarrassing for me and confusing to the LLM!
OK, here it is fixed. Nice thing about workbench is that it just takes a second to edit the prompt, and you can see how the LLM responds, now deciding very early it should be ':'
OK, here it is fixed. Nice thing about workbench is that it just takes a second to edit the prompt, and you can see how the LLM responds, now deciding very early it should be ':'

October 11, 2025 at 2:21 PM
How embarrassing for me and confusing to the LLM!
OK, here it is fixed. Nice thing about workbench is that it just takes a second to edit the prompt, and you can see how the LLM responds, now deciding very early it should be ':'
OK, here it is fixed. Nice thing about workbench is that it just takes a second to edit the prompt, and you can see how the LLM responds, now deciding very early it should be ':'
The lens reveals: the model does NOT go directly from amore to "amor" or "amour" by just dropping or adding letters!
Instead it first "thinks" about the (English) word "love".
In other words: LLMs translate using *concepts*, not tokens.
Instead it first "thinks" about the (English) word "love".
In other words: LLMs translate using *concepts*, not tokens.

October 11, 2025 at 12:02 PM
The lens reveals: the model does NOT go directly from amore to "amor" or "amour" by just dropping or adding letters!
Instead it first "thinks" about the (English) word "love".
In other words: LLMs translate using *concepts*, not tokens.
Instead it first "thinks" about the (English) word "love".
In other words: LLMs translate using *concepts*, not tokens.
Enter a translation prompt: "Italiano: amore, Español: amor, François:".
The workbench doesn't just show you the model's output. It shows the grid of internal states that lead to the output. Researchers call this visualization the "logit lens".
The workbench doesn't just show you the model's output. It shows the grid of internal states that lead to the output. Researchers call this visualization the "logit lens".

October 11, 2025 at 12:02 PM
Enter a translation prompt: "Italiano: amore, Español: amor, François:".
The workbench doesn't just show you the model's output. It shows the grid of internal states that lead to the output. Researchers call this visualization the "logit lens".
The workbench doesn't just show you the model's output. It shows the grid of internal states that lead to the output. Researchers call this visualization the "logit lens".
What does an LLM do when it translates from Italian "amore" to Spanish "amor" or French "amour"?
That's easy! (you might think) Because surely it knows: amore, amor, amour are all based on the same Latin word. It can just drop the "e", or add a "u".
That's easy! (you might think) Because surely it knows: amore, amor, amour are all based on the same Latin word. It can just drop the "e", or add a "u".

October 11, 2025 at 12:02 PM
What does an LLM do when it translates from Italian "amore" to Spanish "amor" or French "amour"?
That's easy! (you might think) Because surely it knows: amore, amor, amour are all based on the same Latin word. It can just drop the "e", or add a "u".
That's easy! (you might think) Because surely it knows: amore, amor, amour are all based on the same Latin word. It can just drop the "e", or add a "u".
The takeaway for me: LLMs separate their token processing from their conceptual processing. Akin to humans' dual route processing of speech.
We need to be aware when an LM is thinking about tokens or concepts.
They do both, and it makes a difference which way it's thinking.
We need to be aware when an LM is thinking about tokens or concepts.
They do both, and it makes a difference which way it's thinking.

September 27, 2025 at 8:54 PM
The takeaway for me: LLMs separate their token processing from their conceptual processing. Akin to humans' dual route processing of speech.
We need to be aware when an LM is thinking about tokens or concepts.
They do both, and it makes a difference which way it's thinking.
We need to be aware when an LM is thinking about tokens or concepts.
They do both, and it makes a difference which way it's thinking.
If token-processing and concept-processing are largely separate, does killing one kill the other? Chris Olah's team in Olsson 2022 hypothesized that ICL emerges from token induction.
@keremsahin22.bsky.social + Sheridan are finding cool ways to look into Olah's induction hypothesis too!
@keremsahin22.bsky.social + Sheridan are finding cool ways to look into Olah's induction hypothesis too!

September 27, 2025 at 8:54 PM
If token-processing and concept-processing are largely separate, does killing one kill the other? Chris Olah's team in Olsson 2022 hypothesized that ICL emerges from token induction.
@keremsahin22.bsky.social + Sheridan are finding cool ways to look into Olah's induction hypothesis too!
@keremsahin22.bsky.social + Sheridan are finding cool ways to look into Olah's induction hypothesis too!
The representation space within the concept induction heads also has a more "meaningful" geometry than the transformer as a whole.
Sheridan discovered (Neurips mechint 2025) that semantic vector arithmetic works better in this space. (Token semantics work in tokenspace.)
arithmetic.baulab.info/
Sheridan discovered (Neurips mechint 2025) that semantic vector arithmetic works better in this space. (Token semantics work in tokenspace.)
arithmetic.baulab.info/

September 27, 2025 at 8:54 PM
The representation space within the concept induction heads also has a more "meaningful" geometry than the transformer as a whole.
Sheridan discovered (Neurips mechint 2025) that semantic vector arithmetic works better in this space. (Token semantics work in tokenspace.)
arithmetic.baulab.info/
Sheridan discovered (Neurips mechint 2025) that semantic vector arithmetic works better in this space. (Token semantics work in tokenspace.)
arithmetic.baulab.info/
If you disable token induction heads and ask the model to copy text with only the concept induction heads, it will NOT copy exactly. It will paraphrase the text.
That happens even for computer code. They copy the BEHAVIOR of the code, but write it in a totally different way!
That happens even for computer code. They copy the BEHAVIOR of the code, but write it in a totally different way!

September 27, 2025 at 8:54 PM
If you disable token induction heads and ask the model to copy text with only the concept induction heads, it will NOT copy exactly. It will paraphrase the text.
That happens even for computer code. They copy the BEHAVIOR of the code, but write it in a totally different way!
That happens even for computer code. They copy the BEHAVIOR of the code, but write it in a totally different way!
An amazing thing about the "concepts" in this 2nd route: they are *not* literal words. They are totally language-independent.
If the target context is in Chinese, they will copy the concept into Chinese. Or patch them between runs to get Italian. They mediate translation.
If the target context is in Chinese, they will copy the concept into Chinese. Or patch them between runs to get Italian. They mediate translation.

September 27, 2025 at 8:54 PM
An amazing thing about the "concepts" in this 2nd route: they are *not* literal words. They are totally language-independent.
If the target context is in Chinese, they will copy the concept into Chinese. Or patch them between runs to get Italian. They mediate translation.
If the target context is in Chinese, they will copy the concept into Chinese. Or patch them between runs to get Italian. They mediate translation.
This second set of text-copying attention heads also shows up in every LLM we tested, and these heads work in a totally different way from token induction heads.
Instead of copying tokens, they copy *concepts*.
Instead of copying tokens, they copy *concepts*.

September 27, 2025 at 8:54 PM
This second set of text-copying attention heads also shows up in every LLM we tested, and these heads work in a totally different way from token induction heads.
Instead of copying tokens, they copy *concepts*.
Instead of copying tokens, they copy *concepts*.
So Sheridan scrutinized copying mechanisms in LLMs and found a SECOND route.
Yes, the token induction of Elhage and Olsson is there.
But there is *another* route where the copying is done in a different way. It shows up it in attention heads that do 2-ahead copying.
bsky.app/profile/sfe...
Yes, the token induction of Elhage and Olsson is there.
But there is *another* route where the copying is done in a different way. It shows up it in attention heads that do 2-ahead copying.
bsky.app/profile/sfe...

September 27, 2025 at 8:54 PM
So Sheridan scrutinized copying mechanisms in LLMs and found a SECOND route.
Yes, the token induction of Elhage and Olsson is there.
But there is *another* route where the copying is done in a different way. It shows up it in attention heads that do 2-ahead copying.
bsky.app/profile/sfe...
Yes, the token induction of Elhage and Olsson is there.
But there is *another* route where the copying is done in a different way. It shows up it in attention heads that do 2-ahead copying.
bsky.app/profile/sfe...
Sherdian's erasure is Bad News for induction heads.
Induction heads are how transformers copy text: they find earlier tokens in identical contexts. (Elhage 2021, Olsson 2022 arxiv.org/abs/2209.11895)
But when that context "what token came before" is erased, how could induction possibly work?
Induction heads are how transformers copy text: they find earlier tokens in identical contexts. (Elhage 2021, Olsson 2022 arxiv.org/abs/2209.11895)
But when that context "what token came before" is erased, how could induction possibly work?

September 27, 2025 at 8:54 PM
Sherdian's erasure is Bad News for induction heads.
Induction heads are how transformers copy text: they find earlier tokens in identical contexts. (Elhage 2021, Olsson 2022 arxiv.org/abs/2209.11895)
But when that context "what token came before" is erased, how could induction possibly work?
Induction heads are how transformers copy text: they find earlier tokens in identical contexts. (Elhage 2021, Olsson 2022 arxiv.org/abs/2209.11895)
But when that context "what token came before" is erased, how could induction possibly work?
Why is that weird? In a transformer each token knows its context, "which tokens came before" and in probes Sheridan found that info is always there when sequences are meaningLESS.
But in meaningFUL phrases, the LM often ERASES the context!!
Exactly opposite of what we expected.
But in meaningFUL phrases, the LM often ERASES the context!!
Exactly opposite of what we expected.

September 27, 2025 at 8:54 PM
Why is that weird? In a transformer each token knows its context, "which tokens came before" and in probes Sheridan found that info is always there when sequences are meaningLESS.
But in meaningFUL phrases, the LM often ERASES the context!!
Exactly opposite of what we expected.
But in meaningFUL phrases, the LM often ERASES the context!!
Exactly opposite of what we expected.
The work starts with a mystery!
In footprints.baulab.info (EMNLP) while dissecting the problem of how LMs read badly tokenized words like " n.ort.he.astern", Sheridan found a huge surprise: they do it by _erasing_ contextual information.
In footprints.baulab.info (EMNLP) while dissecting the problem of how LMs read badly tokenized words like " n.ort.he.astern", Sheridan found a huge surprise: they do it by _erasing_ contextual information.

September 27, 2025 at 8:54 PM
The work starts with a mystery!
In footprints.baulab.info (EMNLP) while dissecting the problem of how LMs read badly tokenized words like " n.ort.he.astern", Sheridan found a huge surprise: they do it by _erasing_ contextual information.
In footprints.baulab.info (EMNLP) while dissecting the problem of how LMs read badly tokenized words like " n.ort.he.astern", Sheridan found a huge surprise: they do it by _erasing_ contextual information.
Who is going to be at #COLM2025?
I want to draw your attention to a COLM paper by my student @sfeucht.bsky.social that has totally changed the way I think and teach about LLM representations. The work is worth knowing.
And you can meet Sheridan at COLM, Oct 7!
bsky.app/profile/sfe...
I want to draw your attention to a COLM paper by my student @sfeucht.bsky.social that has totally changed the way I think and teach about LLM representations. The work is worth knowing.
And you can meet Sheridan at COLM, Oct 7!
bsky.app/profile/sfe...

September 27, 2025 at 8:54 PM
Who is going to be at #COLM2025?
I want to draw your attention to a COLM paper by my student @sfeucht.bsky.social that has totally changed the way I think and teach about LLM representations. The work is worth knowing.
And you can meet Sheridan at COLM, Oct 7!
bsky.app/profile/sfe...
I want to draw your attention to a COLM paper by my student @sfeucht.bsky.social that has totally changed the way I think and teach about LLM representations. The work is worth knowing.
And you can meet Sheridan at COLM, Oct 7!
bsky.app/profile/sfe...
Especially if you're curious about questions like
• What is GPT-OSS 120B thinking inside?
• What does OLMO-32b learn between all its hundreds of checkpoints?
• Why do Qwen3 layers have such different roles from LLama's?
• How does Foundation-Sec reason about cybersecurity?
• What is GPT-OSS 120B thinking inside?
• What does OLMO-32b learn between all its hundreds of checkpoints?
• Why do Qwen3 layers have such different roles from LLama's?
• How does Foundation-Sec reason about cybersecurity?

September 26, 2025 at 6:47 PM
Especially if you're curious about questions like
• What is GPT-OSS 120B thinking inside?
• What does OLMO-32b learn between all its hundreds of checkpoints?
• Why do Qwen3 layers have such different roles from LLama's?
• How does Foundation-Sec reason about cybersecurity?
• What is GPT-OSS 120B thinking inside?
• What does OLMO-32b learn between all its hundreds of checkpoints?
• Why do Qwen3 layers have such different roles from LLama's?
• How does Foundation-Sec reason about cybersecurity?
Announcing a broad expansion of the National Deep Inference Fabric.
This could be relevant to your research...
This could be relevant to your research...

September 26, 2025 at 6:47 PM
Announcing a broad expansion of the National Deep Inference Fabric.
This could be relevant to your research...
This could be relevant to your research...
Nikhil's paper has many other remarkable experiments, including interventions that reveal discrete reasoning steps where the two people in a story are aware or unaware of each others' actions.
The picture is not complete, but it's worth reading and contemplating.
The picture is not complete, but it's worth reading and contemplating.

June 25, 2025 at 3:00 PM
Nikhil's paper has many other remarkable experiments, including interventions that reveal discrete reasoning steps where the two people in a story are aware or unaware of each others' actions.
The picture is not complete, but it's worth reading and contemplating.
The picture is not complete, but it's worth reading and contemplating.
A double dereference can be seen at L35, where patching states on identical words between identical permuted stories changes the answer.
That's because "dereference thing 2" looks for the floating definition of "where is thing 2."
The patch redirects this second indirection!
That's because "dereference thing 2" looks for the floating definition of "where is thing 2."
The patch redirects this second indirection!

June 25, 2025 at 3:00 PM
A double dereference can be seen at L35, where patching states on identical words between identical permuted stories changes the answer.
That's because "dereference thing 2" looks for the floating definition of "where is thing 2."
The patch redirects this second indirection!
That's because "dereference thing 2" looks for the floating definition of "where is thing 2."
The patch redirects this second indirection!
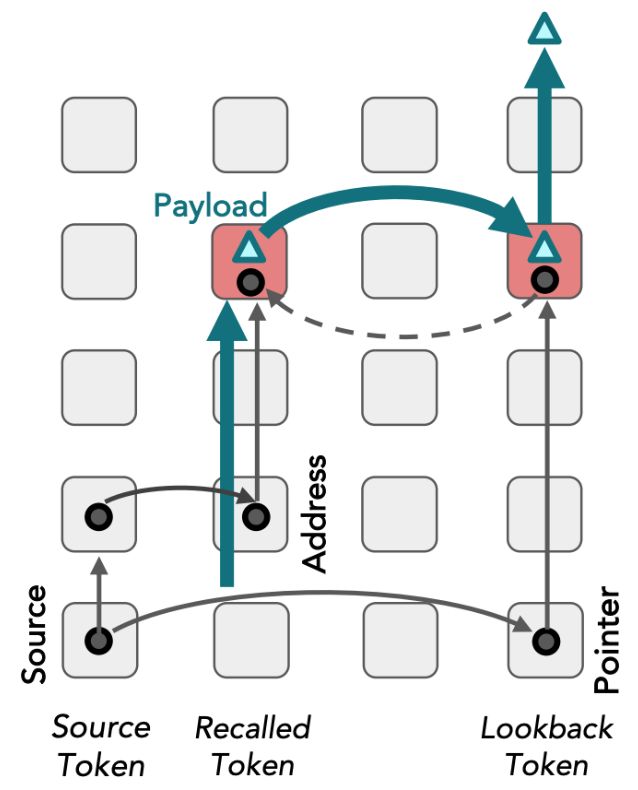
It is strong evidence that what's stored deeper than 50 is not a value but a POINTER dereferenced at 55.
Dai calls these OI's arxiv.org/abs/2409.05448 and
@fjiahai.bsky.social calls them binding IDs arxiv.org/abs/2310.17191
It is a general "lookback" pattern.
Next surprise is nested...
Dai calls these OI's arxiv.org/abs/2409.05448 and
@fjiahai.bsky.social calls them binding IDs arxiv.org/abs/2310.17191
It is a general "lookback" pattern.
Next surprise is nested...
June 25, 2025 at 3:00 PM
It is strong evidence that what's stored deeper than 50 is not a value but a POINTER dereferenced at 55.
Dai calls these OI's arxiv.org/abs/2409.05448 and
@fjiahai.bsky.social calls them binding IDs arxiv.org/abs/2310.17191
It is a general "lookback" pattern.
Next surprise is nested...
Dai calls these OI's arxiv.org/abs/2409.05448 and
@fjiahai.bsky.social calls them binding IDs arxiv.org/abs/2310.17191
It is a general "lookback" pattern.
Next surprise is nested...
There is a lot to unpack in Nikhil's paper and it merits a close reading.
The first thing to understand is his remarkable Fig 2 experiment. Why does the patching of one state, which alters coffee->tea, switch to coffee->beer when you move states deeper than layer 55?
The first thing to understand is his remarkable Fig 2 experiment. Why does the patching of one state, which alters coffee->tea, switch to coffee->beer when you move states deeper than layer 55?

June 25, 2025 at 3:00 PM
There is a lot to unpack in Nikhil's paper and it merits a close reading.
The first thing to understand is his remarkable Fig 2 experiment. Why does the patching of one state, which alters coffee->tea, switch to coffee->beer when you move states deeper than layer 55?
The first thing to understand is his remarkable Fig 2 experiment. Why does the patching of one state, which alters coffee->tea, switch to coffee->beer when you move states deeper than layer 55?
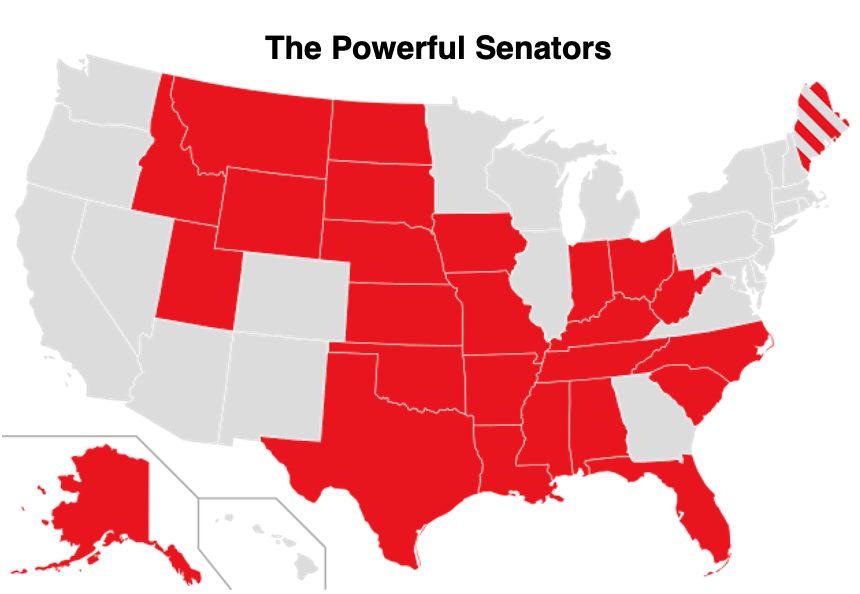
If you live in in ME, KS, WV, IN, LA, MS, TX, ID, NC, AK, TN, MT, ND, AL, NE, SC, or any red state then your senator has outsized influence.
Read here about local impact and how to contact them. They DO listen to voters. They WILL listen to you!
thevisible.net/posts/005-a...
Read here about local impact and how to contact them. They DO listen to voters. They WILL listen to you!
thevisible.net/posts/005-a...
June 3, 2025 at 4:15 PM
If you live in in ME, KS, WV, IN, LA, MS, TX, ID, NC, AK, TN, MT, ND, AL, NE, SC, or any red state then your senator has outsized influence.
Read here about local impact and how to contact them. They DO listen to voters. They WILL listen to you!
thevisible.net/posts/005-a...
Read here about local impact and how to contact them. They DO listen to voters. They WILL listen to you!
thevisible.net/posts/005-a...
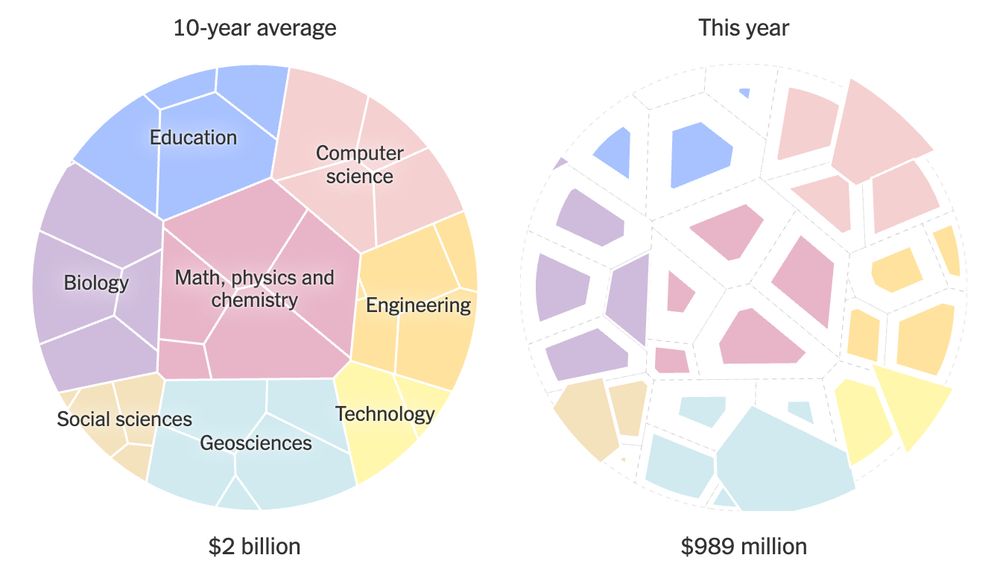
FRIENDS: American science is being decimated by Congress NOW.
Your help is needed to fix this. The current DC plan PERMANENTLY slashes NSF, NIH, all science training. Money isn't redirected—it's gone.
Please read+share what's happening
thevisible.net/posts/004-s...
Your help is needed to fix this. The current DC plan PERMANENTLY slashes NSF, NIH, all science training. Money isn't redirected—it's gone.
Please read+share what's happening
thevisible.net/posts/004-s...
June 3, 2025 at 4:15 PM
FRIENDS: American science is being decimated by Congress NOW.
Your help is needed to fix this. The current DC plan PERMANENTLY slashes NSF, NIH, all science training. Money isn't redirected—it's gone.
Please read+share what's happening
thevisible.net/posts/004-s...
Your help is needed to fix this. The current DC plan PERMANENTLY slashes NSF, NIH, all science training. Money isn't redirected—it's gone.
Please read+share what's happening
thevisible.net/posts/004-s...