



David H Brown
@davhbrown.bsky.social
Neuroscientist & lover of math. Machine Learning @ senseye.co
Reposted by David H Brown

This makes me happy because it confirms my bias that if you really want to impact SOTA, focus on the data. Training data, data preprocessing, post hoc analysis of high-error data points. It’s not flashy but that’s the pay dirt.

Hugging Face's FinePDFs
The largest publicly available corpus sourced exclusively from PDFs, containing about 3 trillion tokens across 475 million documents in 1733 languages.
- Long context
- 3T tokens from high-demand domains like legal and science.
- Heavily improves over SoTA
The largest publicly available corpus sourced exclusively from PDFs, containing about 3 trillion tokens across 475 million documents in 1733 languages.
- Long context
- 3T tokens from high-demand domains like legal and science.
- Heavily improves over SoTA

September 7, 2025 at 10:59 AM
This makes me happy because it confirms my bias that if you really want to impact SOTA, focus on the data. Training data, data preprocessing, post hoc analysis of high-error data points. It’s not flashy but that’s the pay dirt.
The Grug Brained Developer
grugbrain.dev
August 15, 2025 at 3:39 AM

Reposted by David H Brown

I’ve long used FiveThirtyEight’s interactive “Hack Your Way To Scientific Glory” to illustrate the idea of p-hacking when I teach statistics. But ABC/Disney killed the site earlier this month :(
So I made my own with #rstats and Observable and #QuartoPub ! stats.andrewheiss.com/hack-your-way/
So I made my own with #rstats and Observable and #QuartoPub ! stats.andrewheiss.com/hack-your-way/
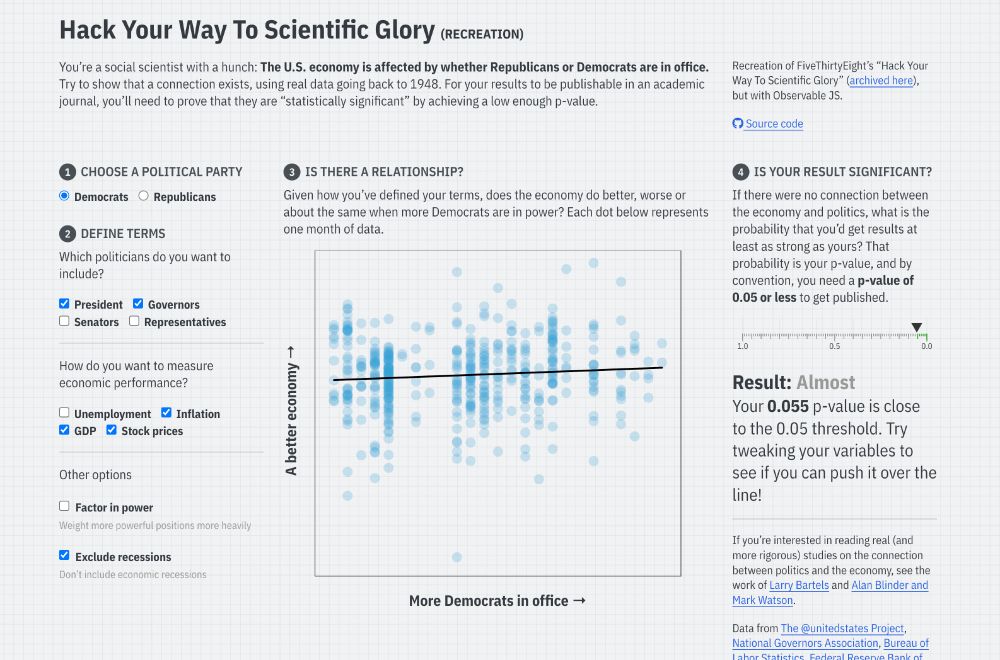
March 20, 2025 at 6:30 PM
I’ve long used FiveThirtyEight’s interactive “Hack Your Way To Scientific Glory” to illustrate the idea of p-hacking when I teach statistics. But ABC/Disney killed the site earlier this month :(
So I made my own with #rstats and Observable and #QuartoPub ! stats.andrewheiss.com/hack-your-way/
So I made my own with #rstats and Observable and #QuartoPub ! stats.andrewheiss.com/hack-your-way/

On the clustering behavior of sliding windows arxiv.org/abs/2503.14393

On the clustering behavior of sliding windows
Things can go spectacularly wrong when clustering timeseries data that has been preprocessed with a sliding window. We highlight three surprising failures that emerge depending on how the window size ...
arxiv.org
March 19, 2025 at 2:48 PM
On the clustering behavior of sliding windows arxiv.org/abs/2503.14393
Reposted by David H Brown


Reposted by David H Brown

This is a super teaching tool, whatever one’s views on PR, because it is interactive and sure to produce good discussion.

In @nytopinion.nytimes.com:
“To escape our two-party trap, we need a better system of electing people to Congress: proportional representation” write Jesse Wegman and Lee Drutman.
“To escape our two-party trap, we need a better system of electing people to Congress: proportional representation” write Jesse Wegman and Lee Drutman.

Opinion | How to Fix America’s Two-Party Problem
Proportional representation could help restore American democracy.
www.nytimes.com
January 16, 2025 at 6:29 AM
This is a super teaching tool, whatever one’s views on PR, because it is interactive and sure to produce good discussion.
Reposted by David H Brown

This might be the first time after 10 years that boosted trees are not the best default choice when working with data in tables.
Instead a pre-trained neural network is, the new TabPFN, as we just published in Nature 🎉
Instead a pre-trained neural network is, the new TabPFN, as we just published in Nature 🎉

January 8, 2025 at 6:00 PM
This might be the first time after 10 years that boosted trees are not the best default choice when working with data in tables.
Instead a pre-trained neural network is, the new TabPFN, as we just published in Nature 🎉
Instead a pre-trained neural network is, the new TabPFN, as we just published in Nature 🎉
Reposted by David H Brown

The Singularity Deck is a multiuse, universal playing card system that allows for an immense number of games to be played including modern and traditional card games. It currently consists of 20 suits all themed after the beginning and the end of the universe.
www.singularity.games/singularity-...
www.singularity.games/singularity-...


November 30, 2024 at 6:54 PM
The Singularity Deck is a multiuse, universal playing card system that allows for an immense number of games to be played including modern and traditional card games. It currently consists of 20 suits all themed after the beginning and the end of the universe.
www.singularity.games/singularity-...
www.singularity.games/singularity-...
Reposted by David H Brown
Modular Magnetic Boards are an ever-growing set of #3Dprinted tiles that let you play a huge number of games on a magnetically reconfigurable board. You can print your own or pick them up from Etsy: singularitygames.etsy.com
November 30, 2024 at 7:04 PM
Modular Magnetic Boards are an ever-growing set of #3Dprinted tiles that let you play a huge number of games on a magnetically reconfigurable board. You can print your own or pick them up from Etsy: singularitygames.etsy.com
Reposted by David H Brown

Introducing the new "NOPE" algorithm
This algorithm will tell you "no" all the time. It has been shown to be up to 95% accurate in situations with a prevalence of 5% and *what is even better* even *more accurate* in rarer diseases
This algorithm will tell you "no" all the time. It has been shown to be up to 95% accurate in situations with a prevalence of 5% and *what is even better* even *more accurate* in rarer diseases
December 2, 2024 at 3:01 PM
Introducing the new "NOPE" algorithm
This algorithm will tell you "no" all the time. It has been shown to be up to 95% accurate in situations with a prevalence of 5% and *what is even better* even *more accurate* in rarer diseases
This algorithm will tell you "no" all the time. It has been shown to be up to 95% accurate in situations with a prevalence of 5% and *what is even better* even *more accurate* in rarer diseases
Reposted by David H Brown

🐦→🦋
The difference between "no evidence that it works," and "evidence that it doesn't work," is
1. extremely confused linguistically
2. extremely important epistemically
3. surprisingly continuous in practice.
The importance of a null study result depends entirely on the power.
The difference between "no evidence that it works," and "evidence that it doesn't work," is
1. extremely confused linguistically
2. extremely important epistemically
3. surprisingly continuous in practice.
The importance of a null study result depends entirely on the power.
November 25, 2024 at 4:54 PM
🐦→🦋
The difference between "no evidence that it works," and "evidence that it doesn't work," is
1. extremely confused linguistically
2. extremely important epistemically
3. surprisingly continuous in practice.
The importance of a null study result depends entirely on the power.
The difference between "no evidence that it works," and "evidence that it doesn't work," is
1. extremely confused linguistically
2. extremely important epistemically
3. surprisingly continuous in practice.
The importance of a null study result depends entirely on the power.
Reposted by David H Brown

Posting a call for help: does anyone know of a good way to simultaneously treat both POTS and Ménière’s disease? Please contact me if you’re either a clinician with experience doing this or a patient who has found a good solution. Context in thread
November 24, 2024 at 4:34 PM
Posting a call for help: does anyone know of a good way to simultaneously treat both POTS and Ménière’s disease? Please contact me if you’re either a clinician with experience doing this or a patient who has found a good solution. Context in thread
Reposted by David H Brown

Part 2: Why do boosted trees outperform deep learning on tabular data??
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n

November 20, 2024 at 5:02 PM
Part 2: Why do boosted trees outperform deep learning on tabular data??
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
Reposted by David H Brown
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
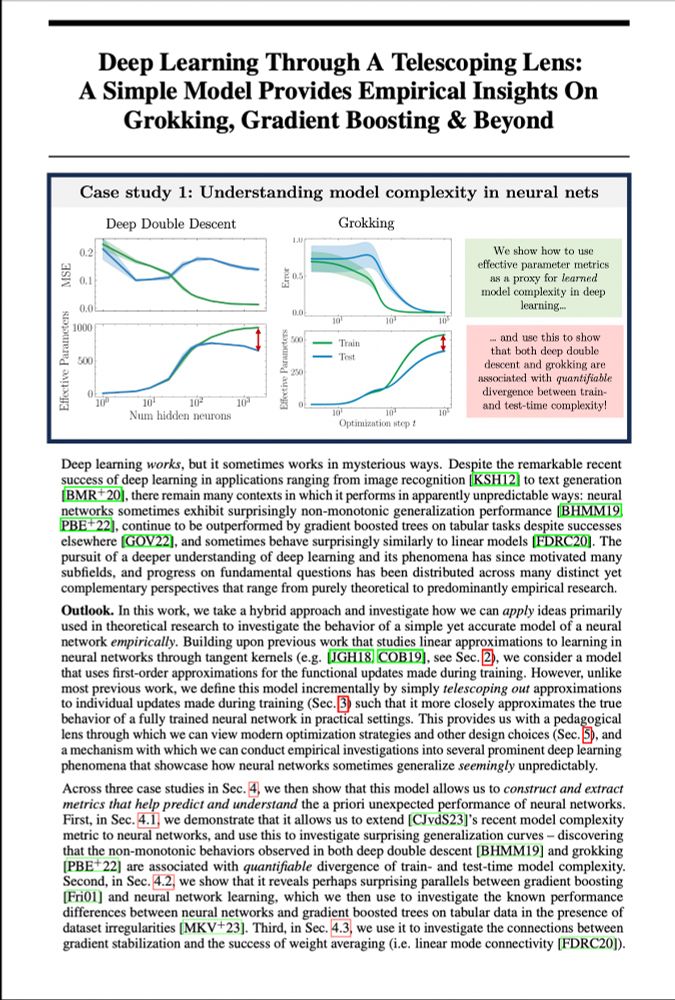
November 18, 2024 at 7:25 PM
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n