



Justin Chih-Yao Chen
@cyjustinchen.bsky.social
Ph.D. Student @unccs, @uncnlp, MURGe-Lab. Student Researcher @Google
RevThink scales positively with model size. We apply RevThink on StrategyQA using models of varying sizes. For each model size, applying our method leads to consistent improvements. Notably, Mistral-7B with our method surpasses Mistral-8x22B by 8.36%, despite the latter having 25x more parameters.

December 2, 2024 at 7:29 PM
RevThink scales positively with model size. We apply RevThink on StrategyQA using models of varying sizes. For each model size, applying our method leads to consistent improvements. Notably, Mistral-7B with our method surpasses Mistral-8x22B by 8.36%, despite the latter having 25x more parameters.
RevThink generalizes to OOD datasets. Compared to the best AnsAug baseline, RevThink achieves 2.11%-5.35% gains on 4 held-out datasets. This suggests that learning to reason backward not only enhances in-domain reasoning but also improves the generalizability to unseen datasets.

December 2, 2024 at 7:29 PM
RevThink generalizes to OOD datasets. Compared to the best AnsAug baseline, RevThink achieves 2.11%-5.35% gains on 4 held-out datasets. This suggests that learning to reason backward not only enhances in-domain reasoning but also improves the generalizability to unseen datasets.
RevThink exhibits sample efficiency. Across multiple reasoning tasks, RevThink consistently outperforms SFT at all levels of the portion of training data (p), even surpassing SFT at p = 1.0 using only 10% of the data on StrategyQA.

December 2, 2024 at 7:29 PM
RevThink exhibits sample efficiency. Across multiple reasoning tasks, RevThink consistently outperforms SFT at all levels of the portion of training data (p), even surpassing SFT at p = 1.0 using only 10% of the data on StrategyQA.
On 8 held-in datasets, RevThink outperforms the best distillation baseline by 6.44%-6.97% using Mistral and Gemma, respectively, and the best data augmentation baseline by 4.52%-5.74%. Also, RevThink provides consistent improvements on a wide range of tasks (commonsense, math, tabular, NLI, logic).

December 2, 2024 at 7:29 PM
On 8 held-in datasets, RevThink outperforms the best distillation baseline by 6.44%-6.97% using Mistral and Gemma, respectively, and the best data augmentation baseline by 4.52%-5.74%. Also, RevThink provides consistent improvements on a wide range of tasks (commonsense, math, tabular, NLI, logic).
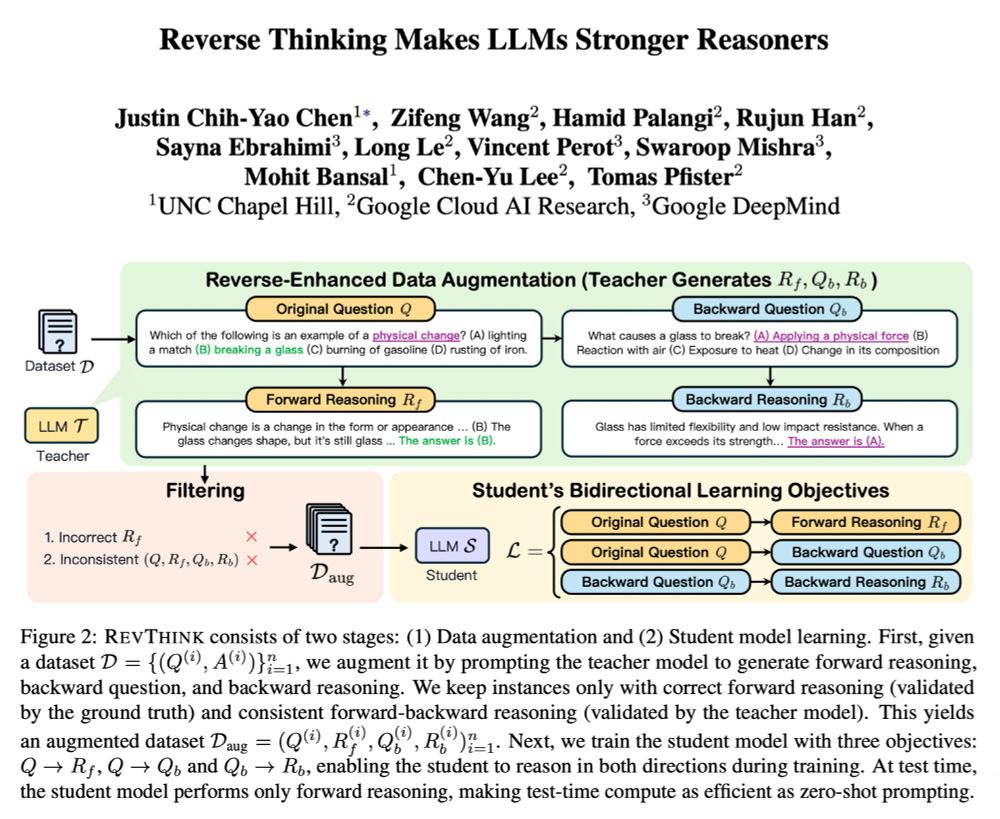
We train the student LM w/ 3 losses:
1. Given Q, generate forward reasoning
2. Given Q, generate backward Q
3. Given backward Q, generate backward reasoning
The student learns bidirectional reasoning in training. At test time, the student only do forward reasoning (as efficient as 0-shot prompting)
1. Given Q, generate forward reasoning
2. Given Q, generate backward Q
3. Given backward Q, generate backward reasoning
The student learns bidirectional reasoning in training. At test time, the student only do forward reasoning (as efficient as 0-shot prompting)

December 2, 2024 at 7:29 PM
We train the student LM w/ 3 losses:
1. Given Q, generate forward reasoning
2. Given Q, generate backward Q
3. Given backward Q, generate backward reasoning
The student learns bidirectional reasoning in training. At test time, the student only do forward reasoning (as efficient as 0-shot prompting)
1. Given Q, generate forward reasoning
2. Given Q, generate backward Q
3. Given backward Q, generate backward reasoning
The student learns bidirectional reasoning in training. At test time, the student only do forward reasoning (as efficient as 0-shot prompting)
We propose RevThink, a framework w/ data augmentation & multi-task objectives. Unlike standard distillations that only fine-tune on Q→A pairs, we use a teacher model to generate backward questions & backward reasoning. The student thus learns from both Q→A and A→Q directions ➡️ 13.53% improvement.

December 2, 2024 at 7:29 PM
We propose RevThink, a framework w/ data augmentation & multi-task objectives. Unlike standard distillations that only fine-tune on Q→A pairs, we use a teacher model to generate backward questions & backward reasoning. The student thus learns from both Q→A and A→Q directions ➡️ 13.53% improvement.
🚨 Reverse Thinking Makes LLMs Stronger Reasoners
We can often reason from a problem to a solution and also in reverse to enhance our overall reasoning. RevThink shows that LLMs can also benefit from reverse thinking 👉 13.53% gains + sample efficiency + strong generalization (on 4 OOD datasets)!
We can often reason from a problem to a solution and also in reverse to enhance our overall reasoning. RevThink shows that LLMs can also benefit from reverse thinking 👉 13.53% gains + sample efficiency + strong generalization (on 4 OOD datasets)!
December 2, 2024 at 7:29 PM
🚨 Reverse Thinking Makes LLMs Stronger Reasoners
We can often reason from a problem to a solution and also in reverse to enhance our overall reasoning. RevThink shows that LLMs can also benefit from reverse thinking 👉 13.53% gains + sample efficiency + strong generalization (on 4 OOD datasets)!
We can often reason from a problem to a solution and also in reverse to enhance our overall reasoning. RevThink shows that LLMs can also benefit from reverse thinking 👉 13.53% gains + sample efficiency + strong generalization (on 4 OOD datasets)!