



Chandan Singh
@csinva.bsky.social
Seeking superhuman explanations.
Senior researcher at Microsoft Research, PhD from UC Berkeley, https://csinva.io/
Senior researcher at Microsoft Research, PhD from UC Berkeley, https://csinva.io/
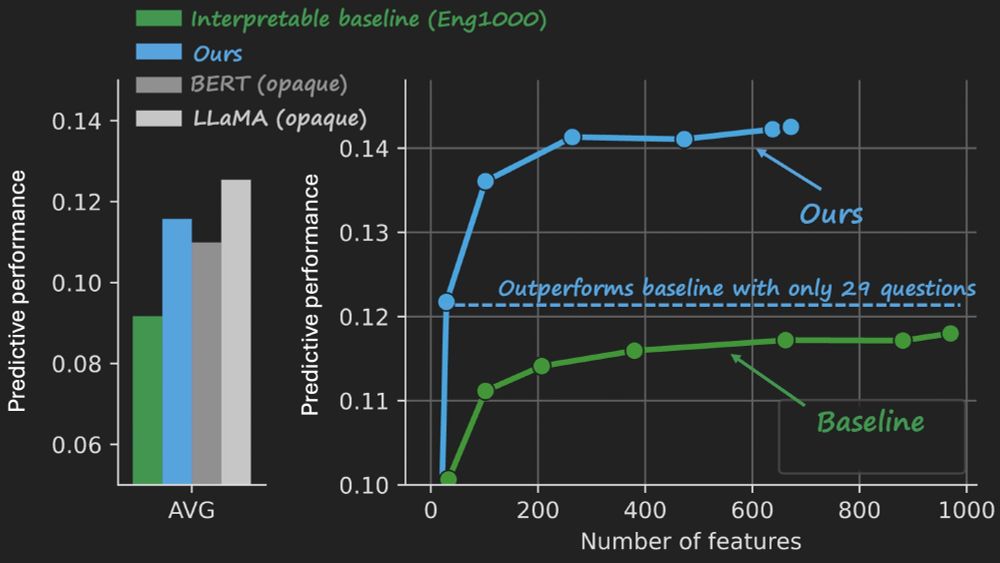
The model is small enough that we can visualize the whole thing. No feature importances or post-hoc summaries, just 35 questions and a map showing their linear weights for each brain voxel.

August 14, 2025 at 2:06 PM
The model is small enough that we can visualize the whole thing. No feature importances or post-hoc summaries, just 35 questions and a map showing their linear weights for each brain voxel.
New paper: Ask 35 simple questions about sentences in a story and use the answers to predict brain responses. Interpretable, compact, & surprisingly high performance in both fMRI and ECoG. 🧵 biorxiv.org/content/10.1...

August 14, 2025 at 2:06 PM
New paper: Ask 35 simple questions about sentences in a story and use the answers to predict brain responses. Interpretable, compact, & surprisingly high performance in both fMRI and ECoG. 🧵 biorxiv.org/content/10.1...
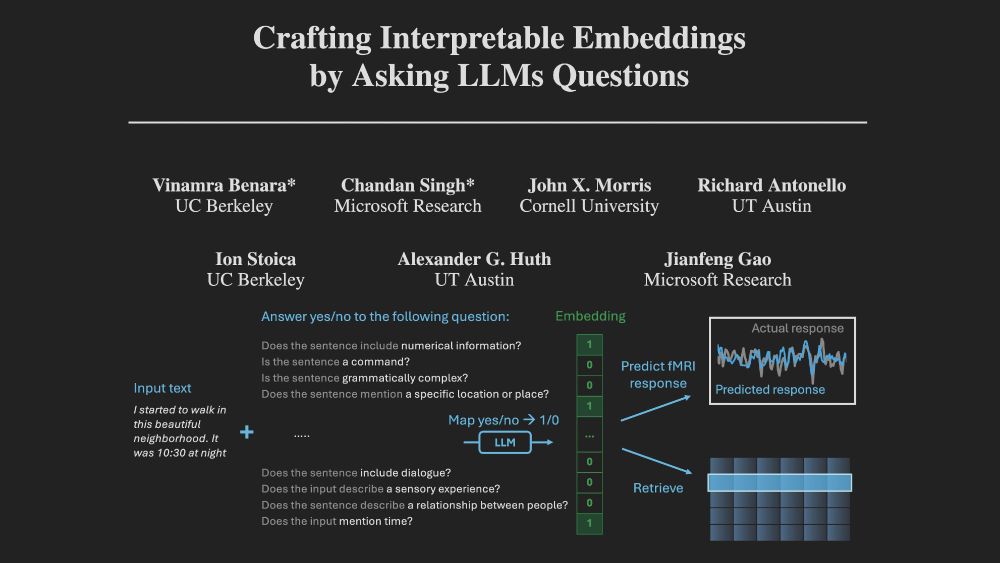
At NeurIPS this week, presenting our work on crafting *interpretable embeddings* by asking yes/no questions to black-box LLMs.
Drop me a message if you want to chat about interpretability/language neuroscience!
Drop me a message if you want to chat about interpretability/language neuroscience!
December 7, 2024 at 3:05 PM
At NeurIPS this week, presenting our work on crafting *interpretable embeddings* by asking yes/no questions to black-box LLMs.
Drop me a message if you want to chat about interpretability/language neuroscience!
Drop me a message if you want to chat about interpretability/language neuroscience!
Science faces an explainability crisis: ML models can predict many natural phenomena but can't explain them
We tackle this issue in language neuroscience by using LLMs to generate *and validate* explanations with targeted follow-up experiments
We tackle this issue in language neuroscience by using LLMs to generate *and validate* explanations with targeted follow-up experiments

November 20, 2024 at 7:31 PM
Science faces an explainability crisis: ML models can predict many natural phenomena but can't explain them
We tackle this issue in language neuroscience by using LLMs to generate *and validate* explanations with targeted follow-up experiments
We tackle this issue in language neuroscience by using LLMs to generate *and validate* explanations with targeted follow-up experiments
Mechanistic interp has made cool findings but struggled to make them useful
We show that "induction heads" found in LLMs can be reverse-engineered to yield accurate & interpretable next-word prediction models
We show that "induction heads" found in LLMs can be reverse-engineered to yield accurate & interpretable next-word prediction models

November 20, 2024 at 7:28 PM
Mechanistic interp has made cool findings but struggled to make them useful
We show that "induction heads" found in LLMs can be reverse-engineered to yield accurate & interpretable next-word prediction models
We show that "induction heads" found in LLMs can be reverse-engineered to yield accurate & interpretable next-word prediction models