



CompVis - Computer Vision and Learning LMU Munich
@compvis.bsky.social
Computer Vision and Learning research group @ LMU Munich, headed by Björn Ommer.
Generative Vision (Stable Diffusion, VQGAN) & Representation Learning
🌐 https://ommer-lab.com
Generative Vision (Stable Diffusion, VQGAN) & Representation Learning
🌐 https://ommer-lab.com
Finally, Felix will present his work on making diffusion transformer training extremely efficient, going from costing multiple months of rent to less than a single night at a conference hotel!
compvis.github.io/tread/
compvis.github.io/tread/
TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training
TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training
compvis.github.io
October 19, 2025 at 6:13 PM
Finally, Felix will present his work on making diffusion transformer training extremely efficient, going from costing multiple months of rent to less than a single night at a conference hotel!
compvis.github.io/tread/
compvis.github.io/tread/
Stefan and Timy will be talking about how we can achieve extremely efficient motion prediction in open-set settings: bsky.app/profile/stef...

🤔 What happens when you poke a scene — and your model has to predict how the world moves in response?
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇

October 19, 2025 at 6:12 PM
Stefan and Timy will be talking about how we can achieve extremely efficient motion prediction in open-set settings: bsky.app/profile/stef...
Pingchuan and Ming will be presenting two works on modeling the evolution of artistic style and disentangled representation learning.
See the following thread for more details bsky.app/profile/pima...
See the following thread for more details bsky.app/profile/pima...

1️⃣ SCFlow: Implicitly Learning Style and Content Disentanglement with Flow Models 🔄
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/

October 19, 2025 at 6:10 PM
Pingchuan and Ming will be presenting two works on modeling the evolution of artistic style and disentangled representation learning.
See the following thread for more details bsky.app/profile/pima...
See the following thread for more details bsky.app/profile/pima...
Reposted by CompVis - Computer Vision and Learning LMU Munich
🧹 CleanDiFT: Diffusion Features without Noise
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
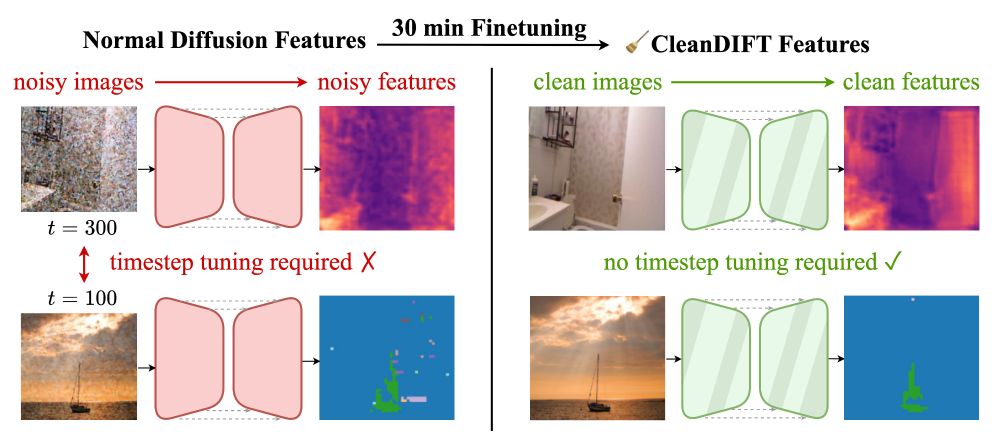
CleanDIFT: Diffusion Features without Noise
CleanDIFT enables extracting Noise-Free, Timestep-Independent Diffusion Features
compvis.github.io
June 9, 2025 at 7:58 AM
🧹 CleanDiFT: Diffusion Features without Noise
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
Continuous Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
@stefanabaumann.bsky.social, Felix Krause, Michael Neumayr, @rmsnorm.bsky.social, Melvin Sevi, @vtaohu.bsky.social, Björn Ommer
P. Sess 3 (ExHall D): Sat 10:30-12:30, #246
compvis.github.io/attribute-co...
@stefanabaumann.bsky.social, Felix Krause, Michael Neumayr, @rmsnorm.bsky.social, Melvin Sevi, @vtaohu.bsky.social, Björn Ommer
P. Sess 3 (ExHall D): Sat 10:30-12:30, #246
compvis.github.io/attribute-co...

Subject-Specific Concept Control
We reveal that certain directions in CLIP text embeddings permit detailed attribute control in text-to-image models.
compvis.github.io
June 9, 2025 at 8:08 AM
Continuous Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
@stefanabaumann.bsky.social, Felix Krause, Michael Neumayr, @rmsnorm.bsky.social, Melvin Sevi, @vtaohu.bsky.social, Björn Ommer
P. Sess 3 (ExHall D): Sat 10:30-12:30, #246
compvis.github.io/attribute-co...
@stefanabaumann.bsky.social, Felix Krause, Michael Neumayr, @rmsnorm.bsky.social, Melvin Sevi, @vtaohu.bsky.social, Björn Ommer
P. Sess 3 (ExHall D): Sat 10:30-12:30, #246
compvis.github.io/attribute-co...
Diff2Flow: Training Flow Matching Models via Diffusion Model Alignment
@joh-schb.bsky.social*, @mgui7.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Poster Session 6 (ExHall D): Sunday 16:00-18:00, # 208
github.com/CompVis/diff...
@joh-schb.bsky.social*, @mgui7.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Poster Session 6 (ExHall D): Sunday 16:00-18:00, # 208
github.com/CompVis/diff...
GitHub - CompVis/diff2flow: [CVPR 2025] Diff2Flow: Training Flow Matching Models via Diffusion Model Alignment
[CVPR 2025] Diff2Flow: Training Flow Matching Models via Diffusion Model Alignment - CompVis/diff2flow
github.com
June 9, 2025 at 8:03 AM
Diff2Flow: Training Flow Matching Models via Diffusion Model Alignment
@joh-schb.bsky.social*, @mgui7.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Poster Session 6 (ExHall D): Sunday 16:00-18:00, # 208
github.com/CompVis/diff...
@joh-schb.bsky.social*, @mgui7.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Poster Session 6 (ExHall D): Sunday 16:00-18:00, # 208
github.com/CompVis/diff...
🧹 CleanDiFT: Diffusion Features without Noise
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
CleanDIFT: Diffusion Features without Noise
CleanDIFT enables extracting Noise-Free, Timestep-Independent Diffusion Features
compvis.github.io
June 9, 2025 at 7:58 AM
🧹 CleanDiFT: Diffusion Features without Noise
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
Reposted by CompVis - Computer Vision and Learning LMU Munich

If you are interested, feel free to check the paper (arxiv.org/abs/2506.02221) or come by at CVPR:
📌 Poster Session 6, Sunday 4:00 to 6:00 PM, Poster #208
📌 Poster Session 6, Sunday 4:00 to 6:00 PM, Poster #208

Diff2Flow: Training Flow Matching Models via Diffusion Model Alignment
Diffusion models have revolutionized generative tasks through high-fidelity outputs, yet flow matching (FM) offers faster inference and empirical performance gains. However, current foundation FM mode...
arxiv.org
June 6, 2025 at 3:48 PM
If you are interested, feel free to check the paper (arxiv.org/abs/2506.02221) or come by at CVPR:
📌 Poster Session 6, Sunday 4:00 to 6:00 PM, Poster #208
📌 Poster Session 6, Sunday 4:00 to 6:00 PM, Poster #208