


Carlo Sferrazza
@carlosferrazza.bsky.social
Postdoc at Berkeley AI Research. PhD from ETH Zurich.
Robotics, Artificial Intelligence, Humanoids, Tactile Sensing.
https://sferrazza.cc
Robotics, Artificial Intelligence, Humanoids, Tactile Sensing.
https://sferrazza.cc
A very fun project at @ucberkeleyofficial.bsky.social, led by amazing Younggyo Seo, with Haoran Geng, Michal Nauman, Zhaoheng Yin, and Pieter Abbeel!
Page: younggyo.me/fast_td3/
Arxiv: arxiv.org/abs/2505.22642
Code: github.com/younggyoseo/...
Page: younggyo.me/fast_td3/
Arxiv: arxiv.org/abs/2505.22642
Code: github.com/younggyoseo/...
FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control
FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control.
younggyo.me
May 29, 2025 at 5:49 PM
A very fun project at @ucberkeleyofficial.bsky.social, led by amazing Younggyo Seo, with Haoran Geng, Michal Nauman, Zhaoheng Yin, and Pieter Abbeel!
Page: younggyo.me/fast_td3/
Arxiv: arxiv.org/abs/2505.22642
Code: github.com/younggyoseo/...
Page: younggyo.me/fast_td3/
Arxiv: arxiv.org/abs/2505.22642
Code: github.com/younggyoseo/...
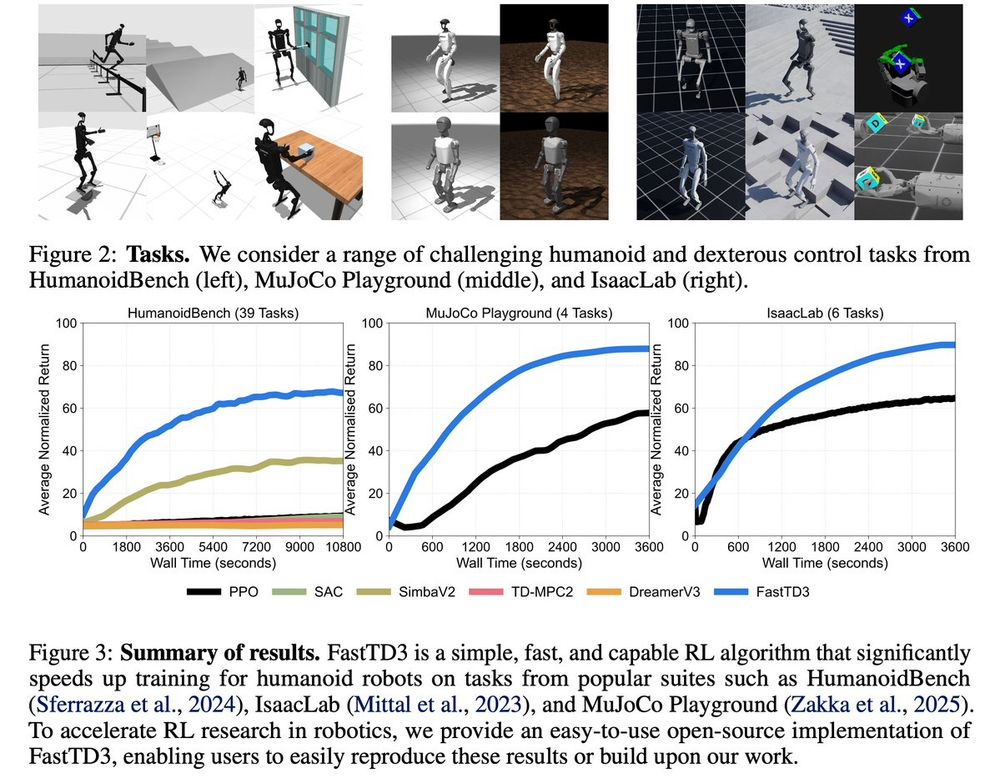
FastTD3 is open-source, and compatible with most sim-to-real robotics frameworks, e.g., MuJoCo Playground and Isaac Lab. All the advances in scaling off-policy RL are now readily available to the robotics community 🤖
May 29, 2025 at 5:49 PM
FastTD3 is open-source, and compatible with most sim-to-real robotics frameworks, e.g., MuJoCo Playground and Isaac Lab. All the advances in scaling off-policy RL are now readily available to the robotics community 🤖
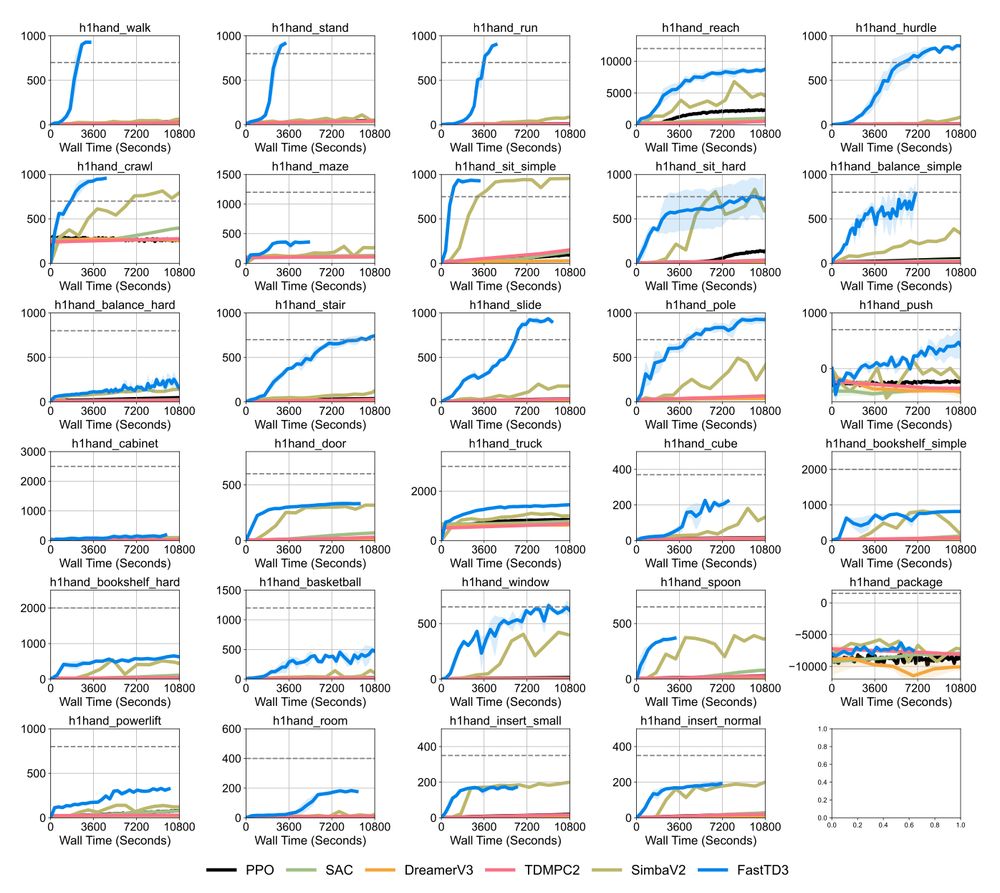
A very cool thing: FastTD3 achieves state-of-the-art performance on most HumanoidBench tasks, even superior to model-based algorithms. All it takes: 128 parallel environments and 1-3 hours of training 🤯
May 29, 2025 at 5:49 PM
A very cool thing: FastTD3 achieves state-of-the-art performance on most HumanoidBench tasks, even superior to model-based algorithms. All it takes: 128 parallel environments and 1-3 hours of training 🤯
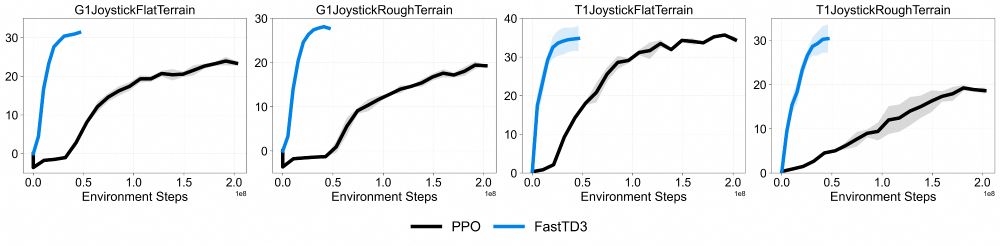
Off-policy methods have pushed RL sample efficiency, but robotics still leans on parallel on-policy RL (PPO) for wall-time gains. FastTD3 gets the best of both worlds!
May 29, 2025 at 5:49 PM
Off-policy methods have pushed RL sample efficiency, but robotics still leans on parallel on-policy RL (PPO) for wall-time gains. FastTD3 gets the best of both worlds!
And co-organizers @sukhijab.bsky.social, @amyxlu.bsky.social, Lenart Treven, Parnian Kassraie, Andrew Wagenmaker, Olivier Bachem, @kjamieson.bsky.social, @arkrause.bsky.social, Pieter Abbeel
April 17, 2025 at 5:53 AM
And co-organizers @sukhijab.bsky.social, @amyxlu.bsky.social, Lenart Treven, Parnian Kassraie, Andrew Wagenmaker, Olivier Bachem, @kjamieson.bsky.social, @arkrause.bsky.social, Pieter Abbeel
With amazing speakers Sergey Levine, Dorsa Sadigh, @djfoster.bsky.social, @ji-won-park.bsky.social, Ben Van Roy, Rishabh Agarwal, @alisongopnik.bsky.social, Masatoshi Uehara
April 17, 2025 at 5:53 AM
With amazing speakers Sergey Levine, Dorsa Sadigh, @djfoster.bsky.social, @ji-won-park.bsky.social, Ben Van Roy, Rishabh Agarwal, @alisongopnik.bsky.social, Masatoshi Uehara
Many robots (and robot videos!), and many awesome collaborators at @ucberkeleyofficial.bsky.social @uoft.bsky.social @cambridgeuni.bsky.social @stanforduniversity.bsky.social @deepmind.google.web.brid.gy – huge shoutout to the entire team!
January 16, 2025 at 10:27 PM
Many robots (and robot videos!), and many awesome collaborators at @ucberkeleyofficial.bsky.social @uoft.bsky.social @cambridgeuni.bsky.social @stanforduniversity.bsky.social @deepmind.google.web.brid.gy – huge shoutout to the entire team!
Very easy installation, it can even run on a single Python notebook: colab.research.google.com/github/googl...
Check out @mujoco.bsky.social’s thread above for all the details.
Can't wait to see the robotics community build on this pipeline and keep pushing the field forward!
Check out @mujoco.bsky.social’s thread above for all the details.
Can't wait to see the robotics community build on this pipeline and keep pushing the field forward!

Google Colab
colab.research.google.com
January 16, 2025 at 10:27 PM
Very easy installation, it can even run on a single Python notebook: colab.research.google.com/github/googl...
Check out @mujoco.bsky.social’s thread above for all the details.
Can't wait to see the robotics community build on this pipeline and keep pushing the field forward!
Check out @mujoco.bsky.social’s thread above for all the details.
Can't wait to see the robotics community build on this pipeline and keep pushing the field forward!
It was really amazing to work on this and see the whole project come together.
Sim-to-real is often an iterative process – Playground makes it seamless.
An open-source ecosystem is essential for integrating new features – check out Madrona-MJX for distillation-free visual RL!
Sim-to-real is often an iterative process – Playground makes it seamless.
An open-source ecosystem is essential for integrating new features – check out Madrona-MJX for distillation-free visual RL!
January 16, 2025 at 10:27 PM
It was really amazing to work on this and see the whole project come together.
Sim-to-real is often an iterative process – Playground makes it seamless.
An open-source ecosystem is essential for integrating new features – check out Madrona-MJX for distillation-free visual RL!
Sim-to-real is often an iterative process – Playground makes it seamless.
An open-source ecosystem is essential for integrating new features – check out Madrona-MJX for distillation-free visual RL!
This work is the result of an amazing collaboration at @ucberkeleyofficial.bsky.social with the other co-leads Josh Jones and Oier Mees, as well as Kyle Stachowicz, Pieter Abbeel, and Sergey Levine!
Paper: arxiv.org/abs/2501.04693
Website: fuse-model.github.io
Paper: arxiv.org/abs/2501.04693
Website: fuse-model.github.io

Beyond Sight: Finetuning Generalist Robot Policies with Heterogeneous Sensors via Language Grounding
Interacting with the world is a multi-sensory experience: achieving effective general-purpose interaction requires making use of all available modalities -- including vision, touch, and audio -- to fi...
arxiv.org
January 13, 2025 at 6:51 PM
This work is the result of an amazing collaboration at @ucberkeleyofficial.bsky.social with the other co-leads Josh Jones and Oier Mees, as well as Kyle Stachowicz, Pieter Abbeel, and Sergey Levine!
Paper: arxiv.org/abs/2501.04693
Website: fuse-model.github.io
Paper: arxiv.org/abs/2501.04693
Website: fuse-model.github.io
We open source the code and the models, as well as the dataset, which comprises 27k (!) action-labeled robot trajectories with visual, inertial, tactile, and auditory observations.
Code: github.com/fuse-model/F...
Models and dataset: huggingface.co/oier-mees/FuSe
Code: github.com/fuse-model/F...
Models and dataset: huggingface.co/oier-mees/FuSe
GitHub - fuse-model/FuSe
Contribute to fuse-model/FuSe development by creating an account on GitHub.
github.com
January 13, 2025 at 6:51 PM
We open source the code and the models, as well as the dataset, which comprises 27k (!) action-labeled robot trajectories with visual, inertial, tactile, and auditory observations.
Code: github.com/fuse-model/F...
Models and dataset: huggingface.co/oier-mees/FuSe
Code: github.com/fuse-model/F...
Models and dataset: huggingface.co/oier-mees/FuSe
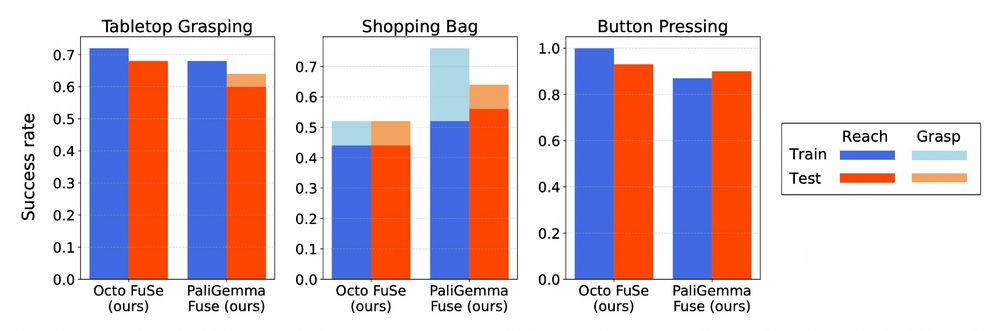
We find that the same general recipe is applicable to generalist policies with diverse architectures, including a large 3B VLA with a PaliGemma vision-language-model backbone.
January 13, 2025 at 6:51 PM
We find that the same general recipe is applicable to generalist policies with diverse architectures, including a large 3B VLA with a PaliGemma vision-language-model backbone.
FuSe policies reason jointly over vision, touch, and sound, enabling tasks such as multimodal disambiguation, generation of object descriptions upon interaction, and compositional cross-modal prompting (e.g., “press the button with the same color as the soft object”).
January 13, 2025 at 6:51 PM
FuSe policies reason jointly over vision, touch, and sound, enabling tasks such as multimodal disambiguation, generation of object descriptions upon interaction, and compositional cross-modal prompting (e.g., “press the button with the same color as the soft object”).
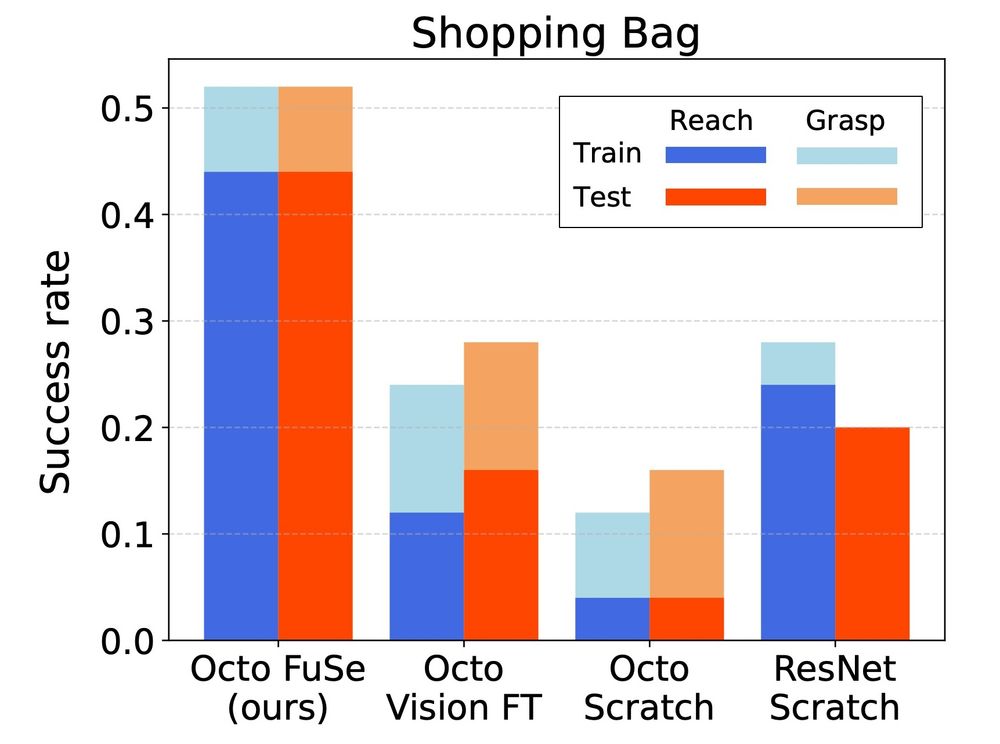
Pretrained generalist robot policies finetuned on multimodal data consistently outperform baselines finetuned only on vision data. This is particularly evident in tasks with partial visual observability, such as grabbing objects from a shopping bag.
January 13, 2025 at 6:51 PM
Pretrained generalist robot policies finetuned on multimodal data consistently outperform baselines finetuned only on vision data. This is particularly evident in tasks with partial visual observability, such as grabbing objects from a shopping bag.
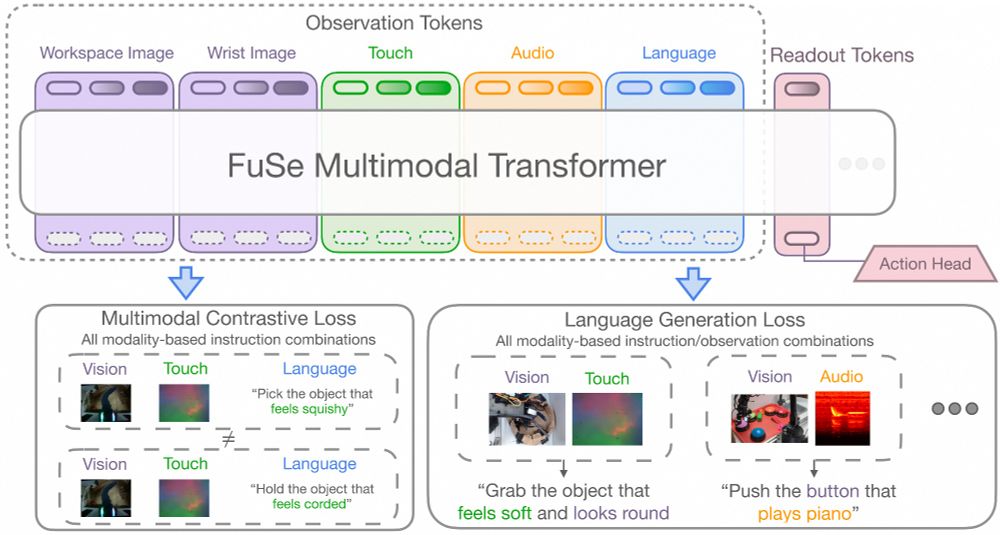
We use language instructions to ground all sensing modalities by introducing two auxiliary losses. In fact, we find that naively finetuning on a small-scale multimodal dataset results in the VLA over-relying on vision, ignoring much sparser tactile and auditory signals.
January 13, 2025 at 6:51 PM
We use language instructions to ground all sensing modalities by introducing two auxiliary losses. In fact, we find that naively finetuning on a small-scale multimodal dataset results in the VLA over-relying on vision, ignoring much sparser tactile and auditory signals.
Work led by amazing @sukhijab.bsky.social at @ucberkeleyofficial.bsky.social AI Research, w/ Stelian Coros, @arkrause.bsky.social , and Pieter Abbeel!
Paper: arxiv.org/abs/2412.12098
Website: sukhijab.github.io/projects/max...
Paper: arxiv.org/abs/2412.12098
Website: sukhijab.github.io/projects/max...
MaxInfoRL: Boosting exploration in reinforcement learning through information gain maximization
Reinforcement learning (RL) algorithms aim to balance exploiting the current best strategy with exploring new options that could lead to higher rewards. Most common RL algorithms use undirected explor...
arxiv.org
December 17, 2024 at 5:47 PM
Work led by amazing @sukhijab.bsky.social at @ucberkeleyofficial.bsky.social AI Research, w/ Stelian Coros, @arkrause.bsky.social , and Pieter Abbeel!
Paper: arxiv.org/abs/2412.12098
Website: sukhijab.github.io/projects/max...
Paper: arxiv.org/abs/2412.12098
Website: sukhijab.github.io/projects/max...
We are also excited to share both Jax and Pytorch implementations, making it simple for RL researchers to integrate MaxInfoRL into their training pipelines.
Jax (built on jaxrl): github.com/sukhijab/max...
Pytorch (based on @araffin.bsky.social‘s SB3): github.com/sukhijab/max...
Jax (built on jaxrl): github.com/sukhijab/max...
Pytorch (based on @araffin.bsky.social‘s SB3): github.com/sukhijab/max...
GitHub - sukhijab/maxinforl_jax
Contribute to sukhijab/maxinforl_jax development by creating an account on GitHub.
github.com
December 17, 2024 at 5:47 PM
We are also excited to share both Jax and Pytorch implementations, making it simple for RL researchers to integrate MaxInfoRL into their training pipelines.
Jax (built on jaxrl): github.com/sukhijab/max...
Pytorch (based on @araffin.bsky.social‘s SB3): github.com/sukhijab/max...
Jax (built on jaxrl): github.com/sukhijab/max...
Pytorch (based on @araffin.bsky.social‘s SB3): github.com/sukhijab/max...
By combining MaxInfoRL with DrQv2 and DrM, this achieves state-of-the-art model-free performance on hard visual control tasks such as DMControl humanoid and dog tasks, improving both sample efficiency and steady-state performance.
December 17, 2024 at 5:47 PM
By combining MaxInfoRL with DrQv2 and DrM, this achieves state-of-the-art model-free performance on hard visual control tasks such as DMControl humanoid and dog tasks, improving both sample efficiency and steady-state performance.
MaxInfoRL is a simple, flexible, and scalable add-on to most RL advancements. We combine it with various algorithms, such as SAC, REDQ, DrQv2, DrM, and more – consistently showing improved performance over the respective backbones.
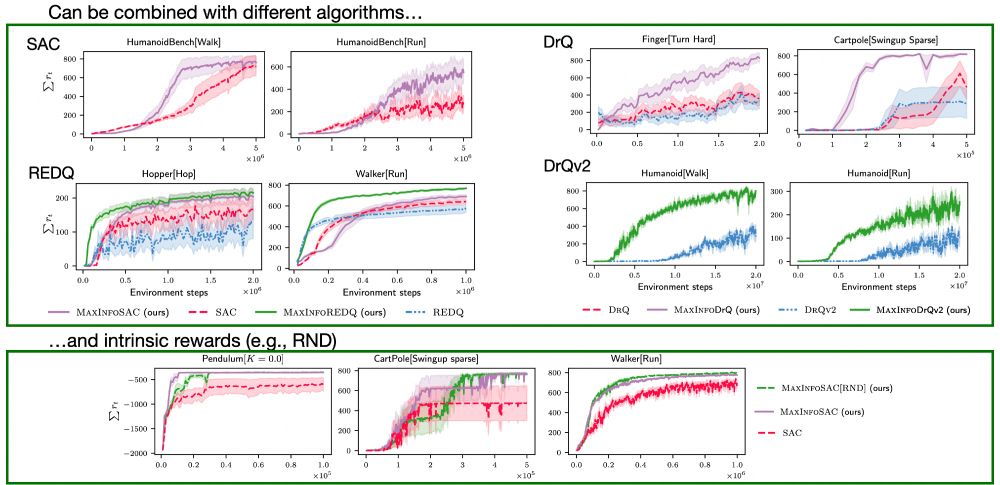
December 17, 2024 at 5:47 PM
MaxInfoRL is a simple, flexible, and scalable add-on to most RL advancements. We combine it with various algorithms, such as SAC, REDQ, DrQv2, DrM, and more – consistently showing improved performance over the respective backbones.