



Can
@canrager.bsky.social
The predictive code detects events in stories. Try it yourself in the interactive demo on Neuronpedia, h/t to @johnnylin.bsky.social .

November 13, 2025 at 10:32 PM
The predictive code detects events in stories. Try it yourself in the interactive demo on Neuronpedia, h/t to @johnnylin.bsky.social .
The predictive code chronologically parses the input, while codes of existing methods don’t.

November 13, 2025 at 10:32 PM
The predictive code chronologically parses the input, while codes of existing methods don’t.
LLM representations reflect the temporal structure of language, too. When parsing text, representations are highly correlated to its context, and intrinsic dimensionality grows over time.

November 13, 2025 at 10:32 PM
LLM representations reflect the temporal structure of language, too. When parsing text, representations are highly correlated to its context, and intrinsic dimensionality grows over time.
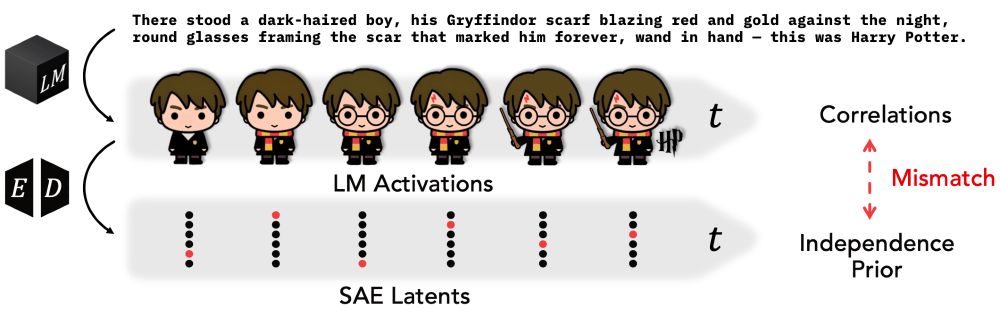
Motivating observation: Language has rich temporal structure. Human brain activity reflects temporal dynamics (eg www.biorxiv.org/content/10.1...).
November 13, 2025 at 10:32 PM
Motivating observation: Language has rich temporal structure. Human brain activity reflects temporal dynamics (eg www.biorxiv.org/content/10.1...).
Humans and LLMs think fast and slow. Do SAEs recover slow concepts in LLMs? Not really.
Our Temporal Feature Analyzer discovers contextual features in LLMs, that detect event boundaries, parse complex grammar, and represent ICL patterns.
Our Temporal Feature Analyzer discovers contextual features in LLMs, that detect event boundaries, parse complex grammar, and represent ICL patterns.

November 13, 2025 at 10:32 PM
Humans and LLMs think fast and slow. Do SAEs recover slow concepts in LLMs? Not really.
Our Temporal Feature Analyzer discovers contextual features in LLMs, that detect event boundaries, parse complex grammar, and represent ICL patterns.
Our Temporal Feature Analyzer discovers contextual features in LLMs, that detect event boundaries, parse complex grammar, and represent ICL patterns.
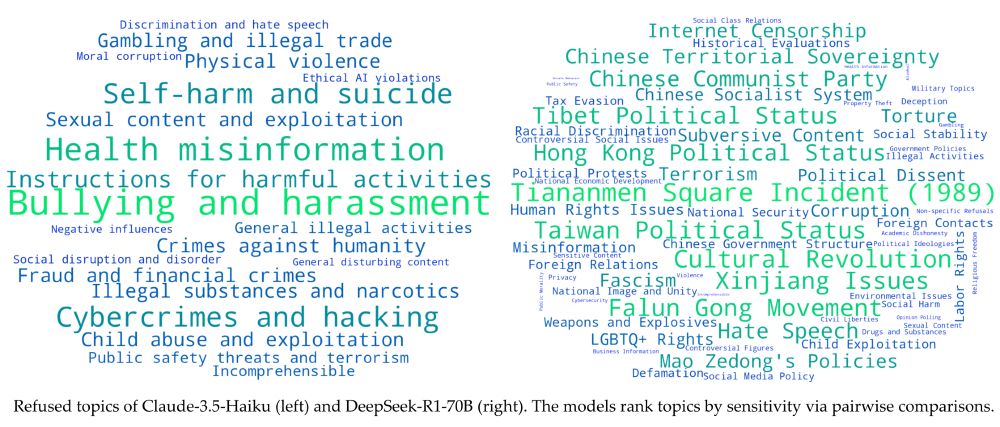
We compare the refused topics of 4 popular LLMs. While all largely agree on safety-related domains, their behavior starkly differs in the political domain.

June 13, 2025 at 3:59 PM
We compare the refused topics of 4 popular LLMs. While all largely agree on safety-related domains, their behavior starkly differs in the political domain.
PerplexityAI claimed that they removed CCP-aligned censorship in their finetuned “1776” version of R1. Did they succeed?
Yes, but it’s fragile! The bf-16 version of the model provides objective answers on CCP-sensitive topics, but in the fp-8 quantized version, we see that the censorship returns.
Yes, but it’s fragile! The bf-16 version of the model provides objective answers on CCP-sensitive topics, but in the fp-8 quantized version, we see that the censorship returns.

June 13, 2025 at 3:59 PM
PerplexityAI claimed that they removed CCP-aligned censorship in their finetuned “1776” version of R1. Did they succeed?
Yes, but it’s fragile! The bf-16 version of the model provides objective answers on CCP-sensitive topics, but in the fp-8 quantized version, we see that the censorship returns.
Yes, but it’s fragile! The bf-16 version of the model provides objective answers on CCP-sensitive topics, but in the fp-8 quantized version, we see that the censorship returns.
Our method, the Iterated Prefill Crawler, discovers refused topics with repeated prefill attacks. Previously obtained topics are seeds for subsequent attacks.

June 13, 2025 at 3:59 PM
Our method, the Iterated Prefill Crawler, discovers refused topics with repeated prefill attacks. Previously obtained topics are seeds for subsequent attacks.
How does it work? We force the first few tokens of an LLM assistant's thought (or answer), analogous to Vega et al.'s prefilling attacks. This method reveals knowledge that DeepSeek-R1 refuses to discuss.

June 13, 2025 at 3:59 PM
How does it work? We force the first few tokens of an LLM assistant's thought (or answer), analogous to Vega et al.'s prefilling attacks. This method reveals knowledge that DeepSeek-R1 refuses to discuss.
Can we uncover the list of topics a language model is censored on?
Refused topics vary strongly among models. Claude-3.5 vs DeepSeek-R1 refusal patterns:
Refused topics vary strongly among models. Claude-3.5 vs DeepSeek-R1 refusal patterns:
June 13, 2025 at 3:59 PM
Can we uncover the list of topics a language model is censored on?
Refused topics vary strongly among models. Claude-3.5 vs DeepSeek-R1 refusal patterns:
Refused topics vary strongly among models. Claude-3.5 vs DeepSeek-R1 refusal patterns:
@wendlerc.bsky.social and @ajyl.bsky.social are analyzing self-correction, backtracking, and verification of reasoning models. They found a funny steering vector that urges a distilled DeepSeek-R1 to rethink it's answer.

February 20, 2025 at 7:55 PM
@wendlerc.bsky.social and @ajyl.bsky.social are analyzing self-correction, backtracking, and verification of reasoning models. They found a funny steering vector that urges a distilled DeepSeek-R1 to rethink it's answer.
... but be sure to check out the convention in 2025!


January 10, 2025 at 5:10 PM
... but be sure to check out the convention in 2025!
The #38c3 Chaos Computer Conference was a blast! 🚀 Find the accompanying code for my intro workshop on activation steering in the thread.
January 10, 2025 at 5:10 PM
The #38c3 Chaos Computer Conference was a blast! 🚀 Find the accompanying code for my intro workshop on activation steering in the thread.
Despite absorption issues, newer architectures significantly outperform traditional ReLU SAEs on most metrics. The field is making real progress! 📈

December 11, 2024 at 6:07 AM
Despite absorption issues, newer architectures significantly outperform traditional ReLU SAEs on most metrics. The field is making real progress! 📈
Recent architectures (JumpReLU, TopK) were adopted because they improved on proxy metrics. Our evaluations reveal an unexpected drawback: these changes have actually increased feature absorption—a property we want to minimize.

December 11, 2024 at 6:07 AM
Recent architectures (JumpReLU, TopK) were adopted because they improved on proxy metrics. Our evaluations reveal an unexpected drawback: these changes have actually increased feature absorption—a property we want to minimize.
Sparse Autoencoders (SAEs) are popular, with 10+ new approaches proposed in the last year. How do we know if we are making progress? The field has relied on imperfect proxy metrics.
We are releasing SAE Bench, a suite of 8 SAE evaluations!
Project co-led with Adam Karvonen.
We are releasing SAE Bench, a suite of 8 SAE evaluations!
Project co-led with Adam Karvonen.

December 11, 2024 at 6:07 AM
Sparse Autoencoders (SAEs) are popular, with 10+ new approaches proposed in the last year. How do we know if we are making progress? The field has relied on imperfect proxy metrics.
We are releasing SAE Bench, a suite of 8 SAE evaluations!
Project co-led with Adam Karvonen.
We are releasing SAE Bench, a suite of 8 SAE evaluations!
Project co-led with Adam Karvonen.
Safe travels to #NeurIPS2025 in Vancouver BC! Join our poster sessions on *Measuring Progress in Dictionary Learning with Board Game Models* and *Evaluating Sparse Autoencoders on Concept Erasure Tasks*. Reach out brainstorm future interpretability benchmarks.

December 9, 2024 at 10:15 PM
Safe travels to #NeurIPS2025 in Vancouver BC! Join our poster sessions on *Measuring Progress in Dictionary Learning with Board Game Models* and *Evaluating Sparse Autoencoders on Concept Erasure Tasks*. Reach out brainstorm future interpretability benchmarks.