


Bryan Wilder
@brwilder.bsky.social
Assistant Professor at Carnegie Mellon. Machine Learning and social impact. https://bryanwilder.github.io/
My takeaway is that algorithm designers should think more broadly about the goals for algorithms in policy settings. It's tempting to just train ML models to maximize predictive performance, but services might be improved a lot with even modest alterations for other goals.
July 8, 2025 at 2:59 PM
My takeaway is that algorithm designers should think more broadly about the goals for algorithms in policy settings. It's tempting to just train ML models to maximize predictive performance, but services might be improved a lot with even modest alterations for other goals.
Using historical data from human services, we then look at how severe learning-targeting tradeoffs really are. It turns out, not that bad! We get most of the possible targeting performance while giving up only a little bit of learning compared to the ideal RCT.
July 8, 2025 at 2:59 PM
Using historical data from human services, we then look at how severe learning-targeting tradeoffs really are. It turns out, not that bad! We get most of the possible targeting performance while giving up only a little bit of learning compared to the ideal RCT.
We introduce a framework for designing allocation policies that optimally trade off between targeting high-need people and learning a treatment effect as accurately as possible. We give efficient algorithms and finite-sample guarantees using a duality-based characterization of the optimal policy.
July 8, 2025 at 2:59 PM
We introduce a framework for designing allocation policies that optimally trade off between targeting high-need people and learning a treatment effect as accurately as possible. We give efficient algorithms and finite-sample guarantees using a duality-based characterization of the optimal policy.
A big factor is that randomizing conflicts with the targeting goal: running a RCT means that people with high predicted risk won't get prioritized for treatment. We wanted to know how sharp the tradeoff really is: does learning treatment effects require giving up on targeting entirely?
July 8, 2025 at 2:59 PM
A big factor is that randomizing conflicts with the targeting goal: running a RCT means that people with high predicted risk won't get prioritized for treatment. We wanted to know how sharp the tradeoff really is: does learning treatment effects require giving up on targeting entirely?
These days, public services are often targeted with predictive algorithms. Targeting helps prioritize people who might be most in need. But, we don't typically have good causal evidence about whether the program we're targeting actually improves outcomes. Why not run RCTs?
July 8, 2025 at 2:59 PM
These days, public services are often targeted with predictive algorithms. Targeting helps prioritize people who might be most in need. But, we don't typically have good causal evidence about whether the program we're targeting actually improves outcomes. Why not run RCTs?
I don't know one way or another, but it's at least a clearer capability to benchmark. And, if a LLM *could* summarize well enough on existing papers, arxiv using it for lower-bar moderation decisions wouldn't distort paper-writing in the future.
May 27, 2025 at 2:24 PM
I don't know one way or another, but it's at least a clearer capability to benchmark. And, if a LLM *could* summarize well enough on existing papers, arxiv using it for lower-bar moderation decisions wouldn't distort paper-writing in the future.
The arXiv summarization use case sounds a lot more sensible. Clear value judgment specified up-front, not outsourced to the LLM: papers should have easily summarized claims and evidence. Resulting incentives for authors seem ok (making sure LLMs can at least parse the paper probably isn't bad).
May 27, 2025 at 2:13 AM
The arXiv summarization use case sounds a lot more sensible. Clear value judgment specified up-front, not outsourced to the LLM: papers should have easily summarized claims and evidence. Resulting incentives for authors seem ok (making sure LLMs can at least parse the paper probably isn't bad).
I would also prefer that these attempts at introducing LLMs be run as a RCT (like ICLR did) so we can learn something. But the tough thing is that even with RCTs it's hard to study the longer-term impact that new incentives will have.
May 27, 2025 at 2:13 AM
I would also prefer that these attempts at introducing LLMs be run as a RCT (like ICLR did) so we can learn something. But the tough thing is that even with RCTs it's hard to study the longer-term impact that new incentives will have.
Reposted by Bryan Wilder

Paper:
Deep RL + mixed integer programming to plan for restless bandits with combinatorial (NP-hard) constraints.
with @brwilder.bsky.social, Elias Khalil, @milindtambe-ai.bsky.social
Poster #416 on Friday @ 3–5:30pm
bsky.app/profile/lily...
Deep RL + mixed integer programming to plan for restless bandits with combinatorial (NP-hard) constraints.
with @brwilder.bsky.social, Elias Khalil, @milindtambe-ai.bsky.social
Poster #416 on Friday @ 3–5:30pm
bsky.app/profile/lily...
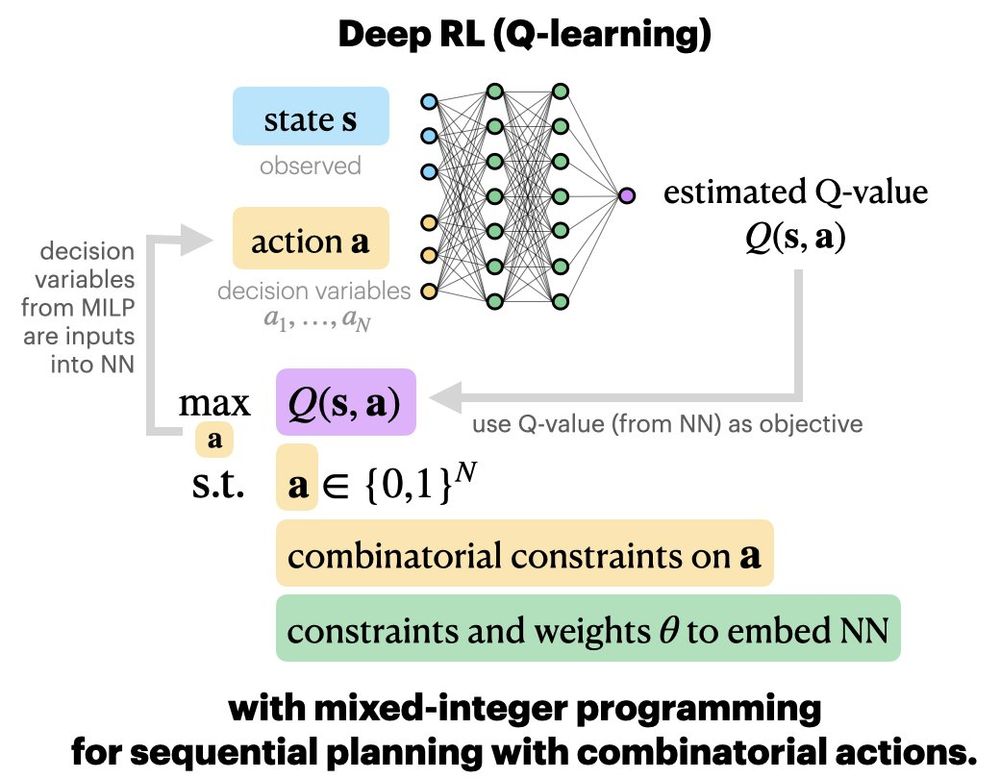
Can we use RL to plan with combinatorial constraints?
Our #ICLR2025 paper combines deep RL with mathematical programming to do so! We embed a trained Q-network into a mixed-integer program, into which we can specify NP-hard constraints.
w/ brwilder.bsky.social, Elias Khalil, Milind Tambe
Our #ICLR2025 paper combines deep RL with mathematical programming to do so! We embed a trained Q-network into a mixed-integer program, into which we can specify NP-hard constraints.
w/ brwilder.bsky.social, Elias Khalil, Milind Tambe
April 24, 2025 at 6:16 AM
Paper:
Deep RL + mixed integer programming to plan for restless bandits with combinatorial (NP-hard) constraints.
with @brwilder.bsky.social, Elias Khalil, @milindtambe-ai.bsky.social
Poster #416 on Friday @ 3–5:30pm
bsky.app/profile/lily...
Deep RL + mixed integer programming to plan for restless bandits with combinatorial (NP-hard) constraints.
with @brwilder.bsky.social, Elias Khalil, @milindtambe-ai.bsky.social
Poster #416 on Friday @ 3–5:30pm
bsky.app/profile/lily...