


Benno Krojer
@bennokrojer.bsky.social
AI PhDing at Mila/McGill (prev FAIR intern). Happily residing in Montreal 🥯❄️
Academic: language grounding, vision+language, interp, rigorous & creative evals, cogsci
Other: many sports, urban explorations, puzzles/quizzes
bennokrojer.com
Academic: language grounding, vision+language, interp, rigorous & creative evals, cogsci
Other: many sports, urban explorations, puzzles/quizzes
bennokrojer.com
Devoured this book in 18 hours, usually not a big fan of audio books!
It covered lots from crowdworker rights, the ideologies (doomers, EA, ...) and the silicon valley startup world to the many big egos and company-internal battles
Great work by @karenhao.bsky.social
It covered lots from crowdworker rights, the ideologies (doomers, EA, ...) and the silicon valley startup world to the many big egos and company-internal battles
Great work by @karenhao.bsky.social

September 22, 2025 at 2:34 AM
Devoured this book in 18 hours, usually not a big fan of audio books!
It covered lots from crowdworker rights, the ideologies (doomers, EA, ...) and the silicon valley startup world to the many big egos and company-internal battles
Great work by @karenhao.bsky.social
It covered lots from crowdworker rights, the ideologies (doomers, EA, ...) and the silicon valley startup world to the many big egos and company-internal battles
Great work by @karenhao.bsky.social
very happy to see the trend of a Behind the Scenes section catching on! transparent & honest science 👌
love the detailed montreal spots mentioned
consider including such a section in your next appendix!
(paper by @a-krishnan.bsky.social arxiv.org/pdf/2504.050...)
love the detailed montreal spots mentioned
consider including such a section in your next appendix!
(paper by @a-krishnan.bsky.social arxiv.org/pdf/2504.050...)

August 13, 2025 at 12:19 PM
very happy to see the trend of a Behind the Scenes section catching on! transparent & honest science 👌
love the detailed montreal spots mentioned
consider including such a section in your next appendix!
(paper by @a-krishnan.bsky.social arxiv.org/pdf/2504.050...)
love the detailed montreal spots mentioned
consider including such a section in your next appendix!
(paper by @a-krishnan.bsky.social arxiv.org/pdf/2504.050...)
Turns out condensing your research into 3min is very hard but also teaches you a lot
Finally the video from Mila's speed science competition is on YouTube!
From a soup of raw pixels to abstract meaning
t.co/RDpu1kR7jM
Finally the video from Mila's speed science competition is on YouTube!
From a soup of raw pixels to abstract meaning
t.co/RDpu1kR7jM
June 20, 2025 at 3:54 PM
Turns out condensing your research into 3min is very hard but also teaches you a lot
Finally the video from Mila's speed science competition is on YouTube!
From a soup of raw pixels to abstract meaning
t.co/RDpu1kR7jM
Finally the video from Mila's speed science competition is on YouTube!
From a soup of raw pixels to abstract meaning
t.co/RDpu1kR7jM
Some reflections at the end:
There's a lot of talk about math reasoning these days, but this project made me appreciate what simple reasoning we humans take for granted, arising in our first months and years of living
As usual i also included "Behind The Scenes" in the Appendix:
There's a lot of talk about math reasoning these days, but this project made me appreciate what simple reasoning we humans take for granted, arising in our first months and years of living
As usual i also included "Behind The Scenes" in the Appendix:

June 13, 2025 at 2:47 PM
Some reflections at the end:
There's a lot of talk about math reasoning these days, but this project made me appreciate what simple reasoning we humans take for granted, arising in our first months and years of living
As usual i also included "Behind The Scenes" in the Appendix:
There's a lot of talk about math reasoning these days, but this project made me appreciate what simple reasoning we humans take for granted, arising in our first months and years of living
As usual i also included "Behind The Scenes" in the Appendix:
I am super grateful to my smart+kind collaborators at Meta who made this a very enjoyable project :)
(Mido Assran Nicolas Ballas @koustuvsinha.com @candaceross.bsky.social @quentin-garrido.bsky.social Mojtaba Komeili)
The Montreal office in general is a very fun place 👇
(Mido Assran Nicolas Ballas @koustuvsinha.com @candaceross.bsky.social @quentin-garrido.bsky.social Mojtaba Komeili)
The Montreal office in general is a very fun place 👇

June 13, 2025 at 2:47 PM
I am super grateful to my smart+kind collaborators at Meta who made this a very enjoyable project :)
(Mido Assran Nicolas Ballas @koustuvsinha.com @candaceross.bsky.social @quentin-garrido.bsky.social Mojtaba Komeili)
The Montreal office in general is a very fun place 👇
(Mido Assran Nicolas Ballas @koustuvsinha.com @candaceross.bsky.social @quentin-garrido.bsky.social Mojtaba Komeili)
The Montreal office in general is a very fun place 👇
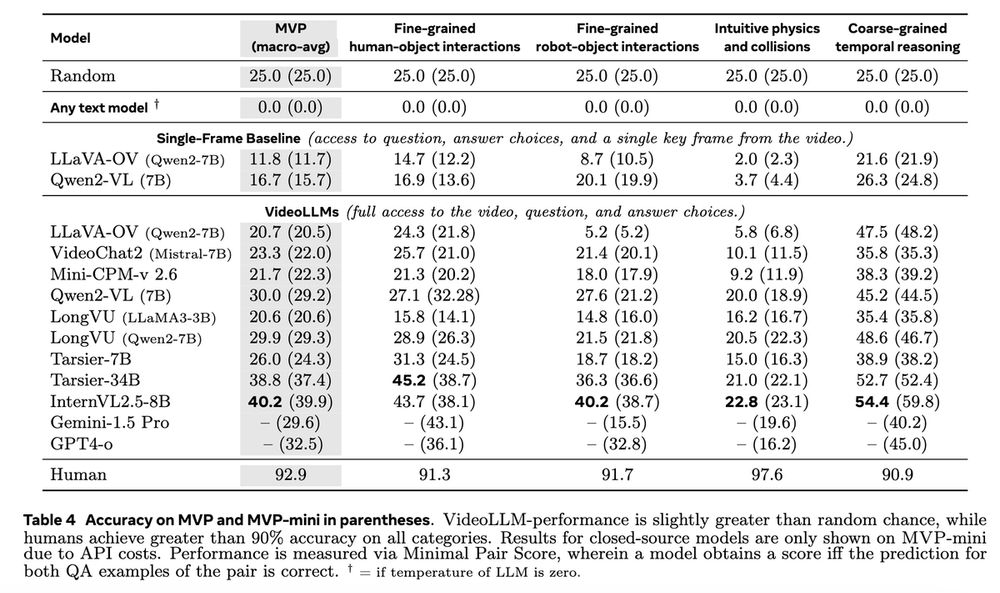
The hardest tasks for current models are still intuitive physics tasks where performance is often below random (In line with the prev. literature)
We encourage the community to use MVPBench to check if the latest VideoLLMs possess a *real* understanding of the physical world!
We encourage the community to use MVPBench to check if the latest VideoLLMs possess a *real* understanding of the physical world!
June 13, 2025 at 2:47 PM
The hardest tasks for current models are still intuitive physics tasks where performance is often below random (In line with the prev. literature)
We encourage the community to use MVPBench to check if the latest VideoLLMs possess a *real* understanding of the physical world!
We encourage the community to use MVPBench to check if the latest VideoLLMs possess a *real* understanding of the physical world!
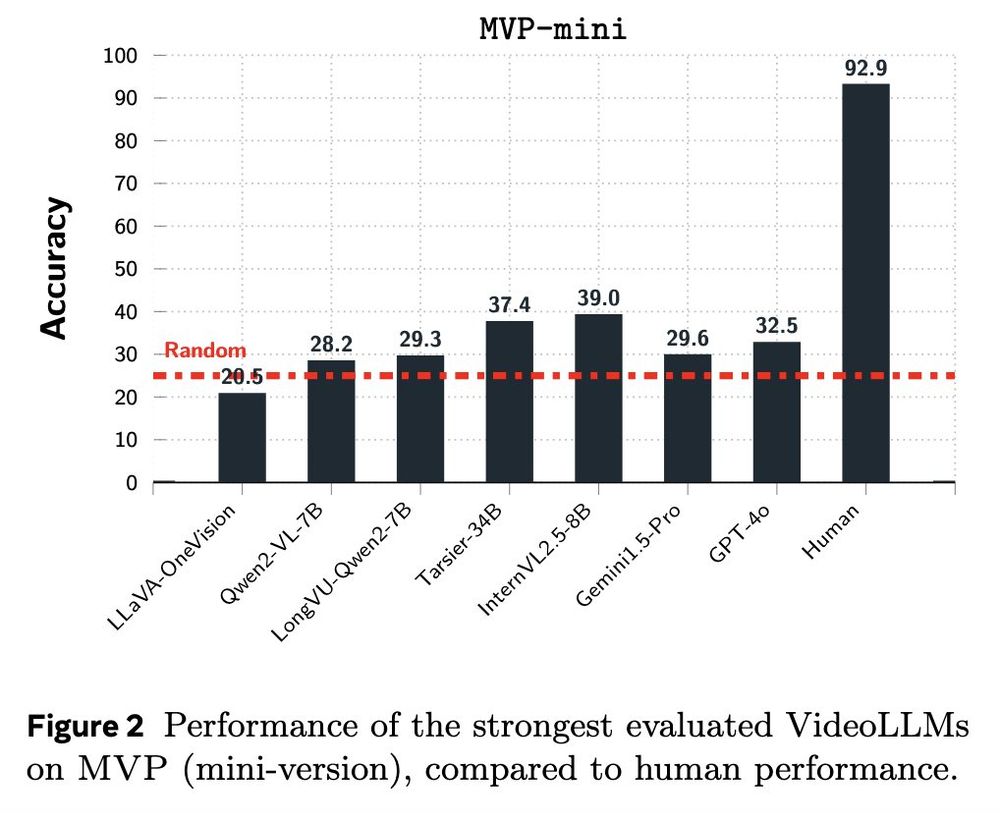
On the other hand even the strongest sota models perform around random chance, with only 2-3 models significantly above random
June 13, 2025 at 2:47 PM
On the other hand even the strongest sota models perform around random chance, with only 2-3 models significantly above random
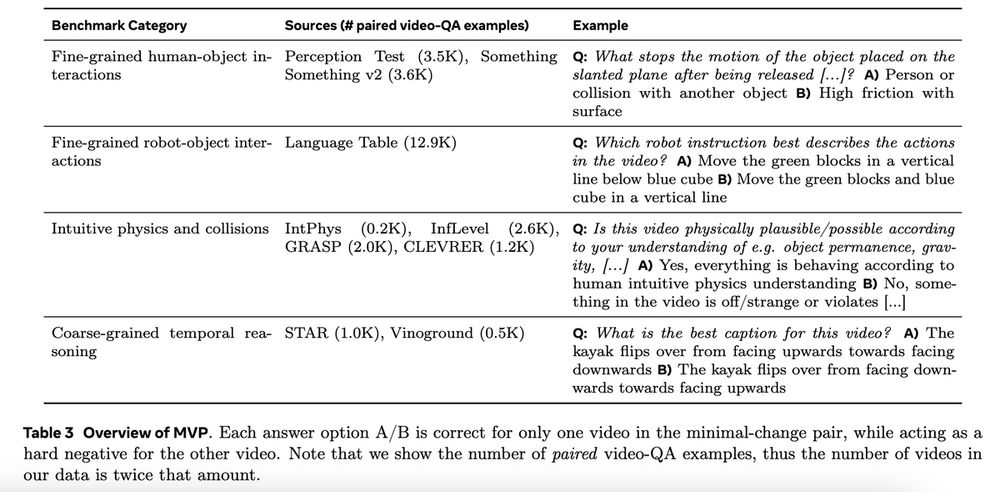
The questions in MVPBench are conceptually simple: relatively short videos with little linguistic or cultural knowledge needed. As a result humans have no problem with these questions, e.g. it is known that even babies do well on various intuitive physics tasks
June 13, 2025 at 2:47 PM
The questions in MVPBench are conceptually simple: relatively short videos with little linguistic or cultural knowledge needed. As a result humans have no problem with these questions, e.g. it is known that even babies do well on various intuitive physics tasks
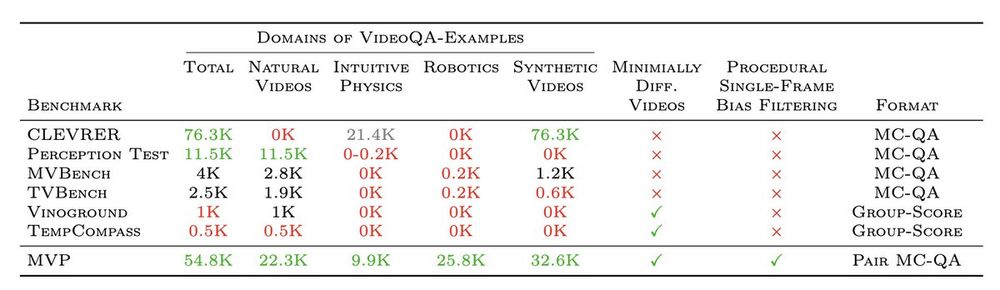
By automating the pairing of highly similar video pairs pairs and unifying different datasets, as well filtering out examples that models can solve with a single-frame, we end up with (probably) the largest and most diverse dataset of its kind:
June 13, 2025 at 2:47 PM
By automating the pairing of highly similar video pairs pairs and unifying different datasets, as well filtering out examples that models can solve with a single-frame, we end up with (probably) the largest and most diverse dataset of its kind:
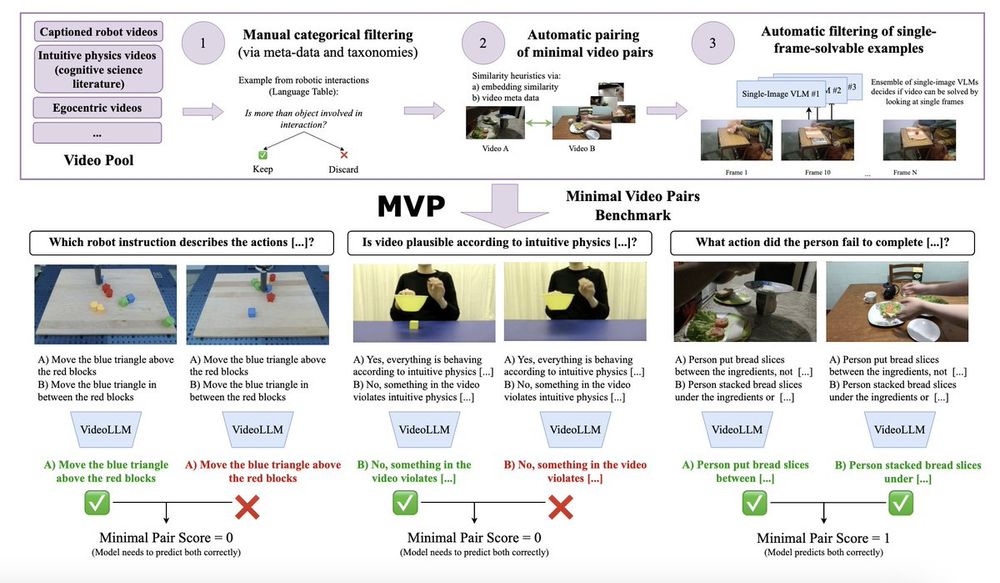
So a solution we propose a 3-step curation framework that results in the Minimal Video Pairs benchmark (MVPBench)
June 13, 2025 at 2:47 PM
So a solution we propose a 3-step curation framework that results in the Minimal Video Pairs benchmark (MVPBench)
We show that seemingly “high-performing” VideoLLMs take various shortcuts on video tasks meant to test physical understanding, such as models falling back to single-frame biases.
In total we analyze 4 such shortcuts and find that model scores often don't change much:
In total we analyze 4 such shortcuts and find that model scores often don't change much:

June 13, 2025 at 2:47 PM
We show that seemingly “high-performing” VideoLLMs take various shortcuts on video tasks meant to test physical understanding, such as models falling back to single-frame biases.
In total we analyze 4 such shortcuts and find that model scores often don't change much:
In total we analyze 4 such shortcuts and find that model scores often don't change much:
Excited to share the results of my recent internship!
We ask 🤔
What subtle shortcuts are VideoLLMs taking on spatio-temporal questions?
And how can we instead curate shortcut-robust examples at a large-scale?
We release: MVPBench
Details 👇🔬
We ask 🤔
What subtle shortcuts are VideoLLMs taking on spatio-temporal questions?
And how can we instead curate shortcut-robust examples at a large-scale?
We release: MVPBench
Details 👇🔬

June 13, 2025 at 2:47 PM
Excited to share the results of my recent internship!
We ask 🤔
What subtle shortcuts are VideoLLMs taking on spatio-temporal questions?
And how can we instead curate shortcut-robust examples at a large-scale?
We release: MVPBench
Details 👇🔬
We ask 🤔
What subtle shortcuts are VideoLLMs taking on spatio-temporal questions?
And how can we instead curate shortcut-robust examples at a large-scale?
We release: MVPBench
Details 👇🔬
Top 99% in Boston 💪
Love these interactive maps
Love these interactive maps
May 30, 2025 at 3:32 PM
Top 99% in Boston 💪
Love these interactive maps
Love these interactive maps
When you forget your leftover rice in the fridge for 3 weeks

May 29, 2025 at 1:09 AM
When you forget your leftover rice in the fridge for 3 weeks
Attend my AI 2025 bootcamp

May 19, 2025 at 8:17 PM
Attend my AI 2025 bootcamp
It would go beyond the effort i want to put in to explain all the technical details but let's do one intuitive example:
Here we want to know at what point the model resolves that "it" refers to "Patchscopes" --> you could apply logitlens to it (www.lesswrong.com/posts/AcKRB8...) or... 1/2
Here we want to know at what point the model resolves that "it" refers to "Patchscopes" --> you could apply logitlens to it (www.lesswrong.com/posts/AcKRB8...) or... 1/2

May 5, 2025 at 9:40 PM
It would go beyond the effort i want to put in to explain all the technical details but let's do one intuitive example:
Here we want to know at what point the model resolves that "it" refers to "Patchscopes" --> you could apply logitlens to it (www.lesswrong.com/posts/AcKRB8...) or... 1/2
Here we want to know at what point the model resolves that "it" refers to "Patchscopes" --> you could apply logitlens to it (www.lesswrong.com/posts/AcKRB8...) or... 1/2
Day 13:
(the original mega-thread has become too long and nested so reposting now as a new strategy)
Patchscopes: A Unifying Framework for Inspecting
Hidden Representations of Language Models
A few notes below 👇 I took less digital notes this time as i was sitting outside in the sun reading 🌞
(the original mega-thread has become too long and nested so reposting now as a new strategy)
Patchscopes: A Unifying Framework for Inspecting
Hidden Representations of Language Models
A few notes below 👇 I took less digital notes this time as i was sitting outside in the sun reading 🌞


May 5, 2025 at 9:40 PM
Day 13:
(the original mega-thread has become too long and nested so reposting now as a new strategy)
Patchscopes: A Unifying Framework for Inspecting
Hidden Representations of Language Models
A few notes below 👇 I took less digital notes this time as i was sitting outside in the sun reading 🌞
(the original mega-thread has become too long and nested so reposting now as a new strategy)
Patchscopes: A Unifying Framework for Inspecting
Hidden Representations of Language Models
A few notes below 👇 I took less digital notes this time as i was sitting outside in the sun reading 🌞
Super useful! I didn't actually know this trick

April 26, 2025 at 8:04 PM
Super useful! I didn't actually know this trick
Overall I loved the paper, got lots of inspiration from it and would love to be part of a similar project in the future: for example an empirical investigation of many AI papers to answer "To what extent is AI is a science?"

April 15, 2025 at 9:56 PM
Overall I loved the paper, got lots of inspiration from it and would love to be part of a similar project in the future: for example an empirical investigation of many AI papers to answer "To what extent is AI is a science?"
2) For me IA might be most valuable because it gives us new concepts and frames

April 15, 2025 at 9:56 PM
2) For me IA might be most valuable because it gives us new concepts and frames
Let me highlight two passages i found very cool:
1) maybe people *outside* of a field only see the field's best papers and thus think it is impactful while people *outside* the field are exposed to all the chaotic average paper
1) maybe people *outside* of a field only see the field's best papers and thus think it is impactful while people *outside* the field are exposed to all the chaotic average paper

April 15, 2025 at 9:56 PM
Let me highlight two passages i found very cool:
1) maybe people *outside* of a field only see the field's best papers and thus think it is impactful while people *outside* the field are exposed to all the chaotic average paper
1) maybe people *outside* of a field only see the field's best papers and thus think it is impactful while people *outside* the field are exposed to all the chaotic average paper
So what are the results? Overall it looks pretty good for I&A research!
There's tons of interesting nuanced insights in the paper, so here are just some I noted down:
There's tons of interesting nuanced insights in the paper, so here are just some I noted down:

April 15, 2025 at 9:56 PM
So what are the results? Overall it looks pretty good for I&A research!
There's tons of interesting nuanced insights in the paper, so here are just some I noted down:
There's tons of interesting nuanced insights in the paper, so here are just some I noted down:
So the next challenge is how to define and operationalize "impact": For that the authors adopt a citation graph analysis and surveys (plus qualitative analyses of those)
--> this is called a mixed-methods analysis in social sciences
--> this is called a mixed-methods analysis in social sciences

April 15, 2025 at 9:56 PM
So the next challenge is how to define and operationalize "impact": For that the authors adopt a citation graph analysis and surveys (plus qualitative analyses of those)
--> this is called a mixed-methods analysis in social sciences
--> this is called a mixed-methods analysis in social sciences
More detailed notes (there was much to think about: every second sentence was probably worth a minute-long ponder):
Arguably the hardest challenge is how to define what "interpretability and analysis" means. They adopt a quite broad definition but do a good job imo, also including some eval work
Arguably the hardest challenge is how to define what "interpretability and analysis" means. They adopt a quite broad definition but do a good job imo, also including some eval work

April 15, 2025 at 9:56 PM
More detailed notes (there was much to think about: every second sentence was probably worth a minute-long ponder):
Arguably the hardest challenge is how to define what "interpretability and analysis" means. They adopt a quite broad definition but do a good job imo, also including some eval work
Arguably the hardest challenge is how to define what "interpretability and analysis" means. They adopt a quite broad definition but do a good job imo, also including some eval work