


Ameya P.
@bayesiankitten.bsky.social
Postdoctoral Researcher @ Bethgelab, University of Tübingen
Benchmarking | LLM Agents | Data-Centric ML | Continual Learning | Unlearning
drimpossible.github.io
Benchmarking | LLM Agents | Data-Centric ML | Continual Learning | Unlearning
drimpossible.github.io
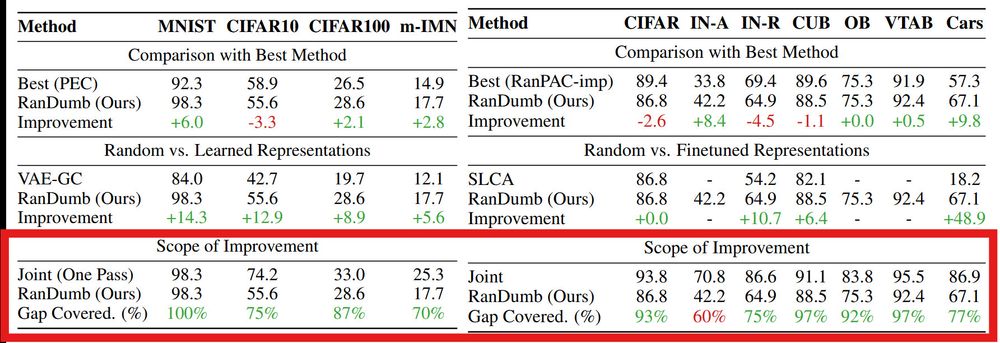
Can better representation learning help? No!
RanDumb recovers 70-90% of the joint performance.
Forgetting isn't the main issue—the benchmarks are too toy!
Key Point: Current OCL benchmarks are too constrained for any effective learning of online continual representations!
RanDumb recovers 70-90% of the joint performance.
Forgetting isn't the main issue—the benchmarks are too toy!
Key Point: Current OCL benchmarks are too constrained for any effective learning of online continual representations!
December 13, 2024 at 6:53 PM
Can better representation learning help? No!
RanDumb recovers 70-90% of the joint performance.
Forgetting isn't the main issue—the benchmarks are too toy!
Key Point: Current OCL benchmarks are too constrained for any effective learning of online continual representations!
RanDumb recovers 70-90% of the joint performance.
Forgetting isn't the main issue—the benchmarks are too toy!
Key Point: Current OCL benchmarks are too constrained for any effective learning of online continual representations!
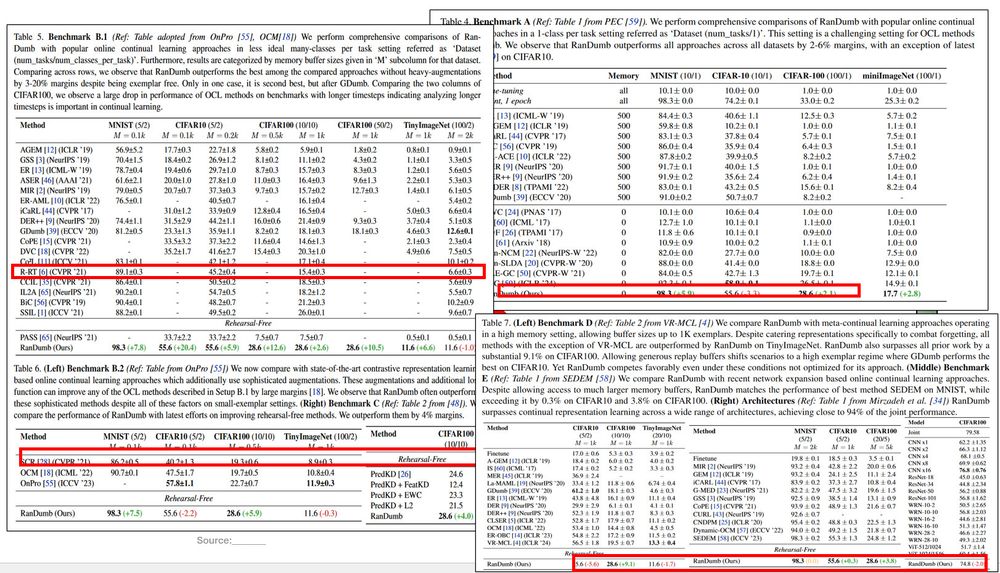
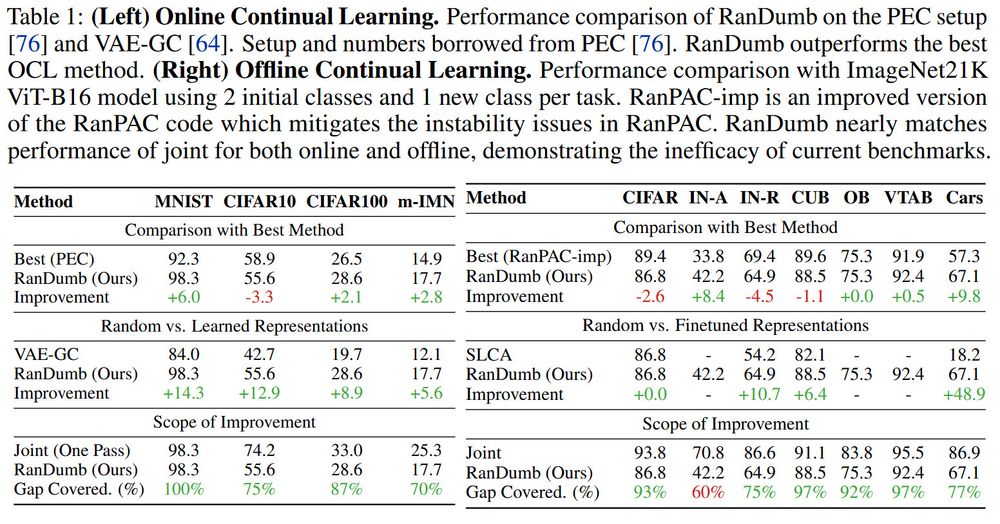
Across a wide range of online continual learning benchmarks-- RanDumb consistently surpasses prior methods (even latest contrastive & meta strategies), often by surprisingly large margins!
December 13, 2024 at 6:53 PM
Across a wide range of online continual learning benchmarks-- RanDumb consistently surpasses prior methods (even latest contrastive & meta strategies), often by surprisingly large margins!
Continual Learning assumes deep representations learned outperform old school kernel classifiers (as in supervised DL). But this isn't validated!!
Why might it not work? Updates are limited and networks may not converge.
We find: OCL representations are severely undertrained!
Why might it not work? Updates are limited and networks may not converge.
We find: OCL representations are severely undertrained!
December 13, 2024 at 6:52 PM
Continual Learning assumes deep representations learned outperform old school kernel classifiers (as in supervised DL). But this isn't validated!!
Why might it not work? Updates are limited and networks may not converge.
We find: OCL representations are severely undertrained!
Why might it not work? Updates are limited and networks may not converge.
We find: OCL representations are severely undertrained!
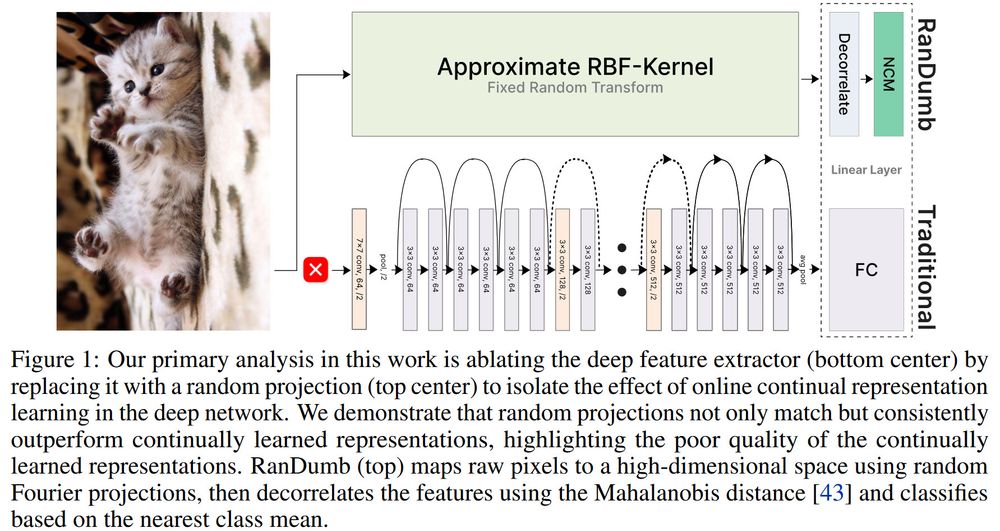
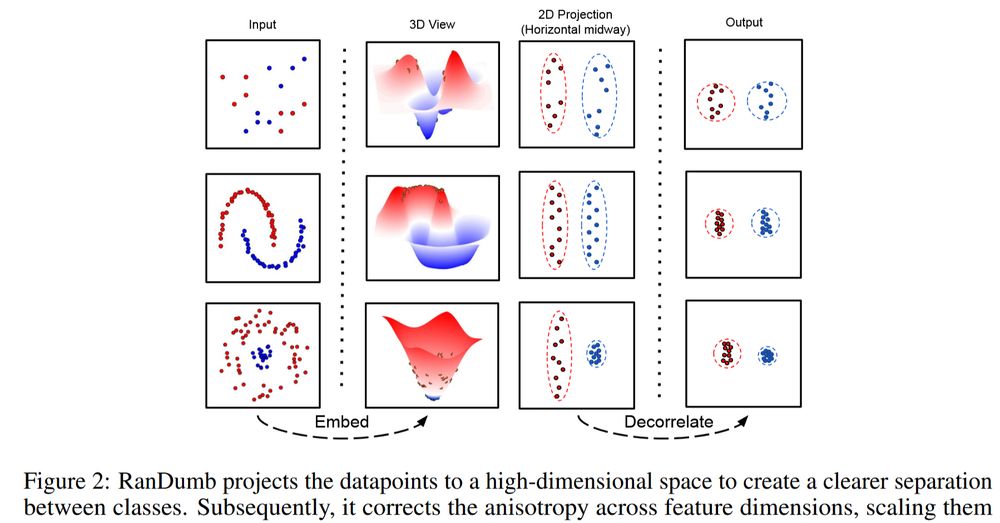
How RanDumb works: Fix a random embedder to transform raw pixels. Train a linear classifier on top—single pass, one sample at a time, no stored exemplars. Order-invariant, worst-case ready🚀
Looks familiar? This is streaming (approx.) Kernel LDA!!
Looks familiar? This is streaming (approx.) Kernel LDA!!
December 13, 2024 at 6:52 PM
How RanDumb works: Fix a random embedder to transform raw pixels. Train a linear classifier on top—single pass, one sample at a time, no stored exemplars. Order-invariant, worst-case ready🚀
Looks familiar? This is streaming (approx.) Kernel LDA!!
Looks familiar? This is streaming (approx.) Kernel LDA!!
New Work: RanDumb!🚀
Poster @NeurIPS, East Hall #1910- come say hi👋
Core claim: Random representations Outperform Online Continual Learning Methods!
How: We replace the deep network by a *random projection* and linear clf, yet outperform all OCL methods by huge margins [1/n]
Poster @NeurIPS, East Hall #1910- come say hi👋
Core claim: Random representations Outperform Online Continual Learning Methods!
How: We replace the deep network by a *random projection* and linear clf, yet outperform all OCL methods by huge margins [1/n]
December 13, 2024 at 6:50 PM
New Work: RanDumb!🚀
Poster @NeurIPS, East Hall #1910- come say hi👋
Core claim: Random representations Outperform Online Continual Learning Methods!
How: We replace the deep network by a *random projection* and linear clf, yet outperform all OCL methods by huge margins [1/n]
Poster @NeurIPS, East Hall #1910- come say hi👋
Core claim: Random representations Outperform Online Continual Learning Methods!
How: We replace the deep network by a *random projection* and linear clf, yet outperform all OCL methods by huge margins [1/n]