


Atlas Wang
@atlaswang.bsky.social
https://www.vita-group.space/ 👨🏫 UT Austin ML Professor (on leave)
https://www.xtxmarkets.com/ 🏦 XTX Markets Research Director (NYC AI Lab)
Superpower is trying everything 🪅
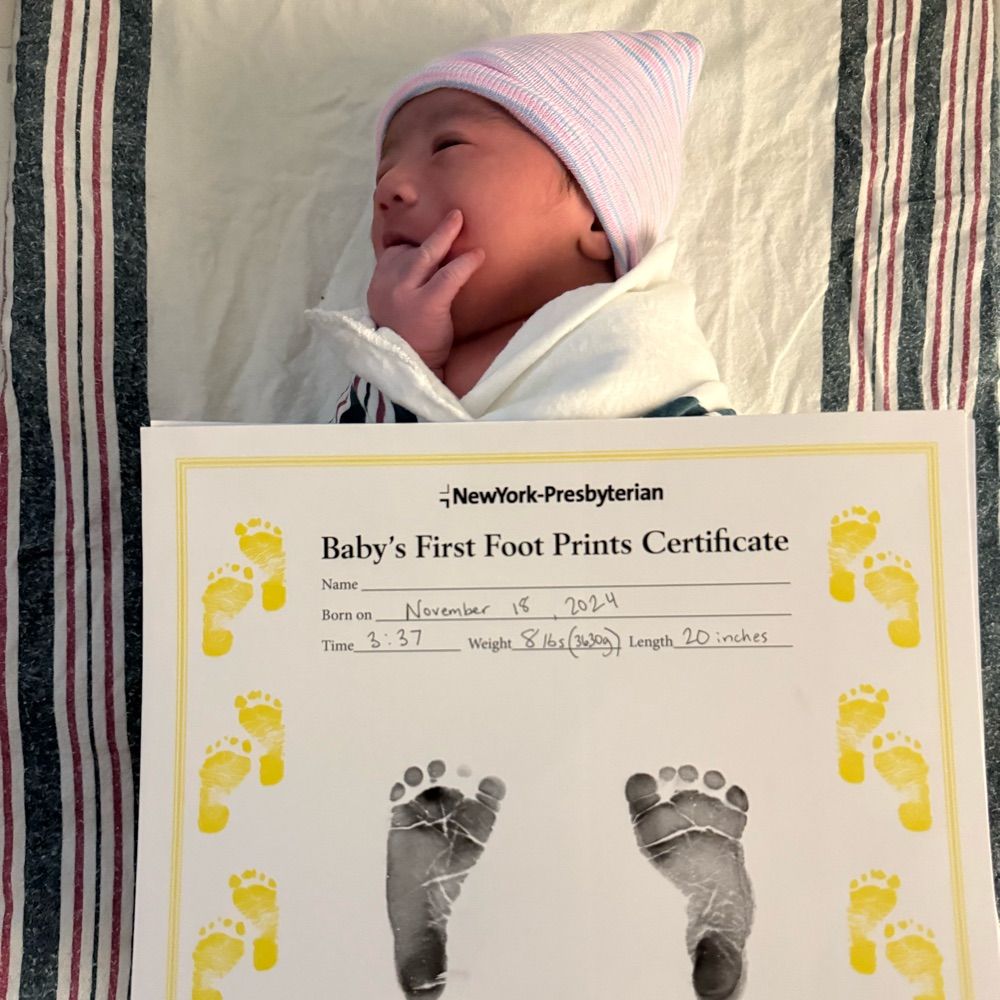
Newest focus: training next-generation super intelligence - Preview above 👶
https://www.xtxmarkets.com/ 🏦 XTX Markets Research Director (NYC AI Lab)
Superpower is trying everything 🪅
Newest focus: training next-generation super intelligence - Preview above 👶

Practically, enforce the right symmetries + keep weight distributions low-entropy-> you may get symbolic generalization “for free.” Lines up with grokking & reasoning-finetuning we keep seeing.
If emergent reasoning, implicit alignment, or theory-catching-practice excites you, dive in & poke holes!
If emergent reasoning, implicit alignment, or theory-catching-practice excites you, dive in & poke holes!
June 30, 2025 at 10:14 AM
Practically, enforce the right symmetries + keep weight distributions low-entropy-> you may get symbolic generalization “for free.” Lines up with grokking & reasoning-finetuning we keep seeing.
If emergent reasoning, implicit alignment, or theory-catching-practice excites you, dive in & poke holes!
If emergent reasoning, implicit alignment, or theory-catching-practice excites you, dive in & poke holes!
Key ideas:
• #EmergentReasoning — provably, no external logic engine needed.
• #GeometricLens — lift weights to a probability measure & watch training as a Wasserstein gradient flow; messy SGD turns into clean geometry.
• #Compositionality — small rules snap into big ones. (3/n)
• #EmergentReasoning — provably, no external logic engine needed.
• #GeometricLens — lift weights to a probability measure & watch training as a Wasserstein gradient flow; messy SGD turns into clean geometry.
• #Compositionality — small rules snap into big ones. (3/n)
June 30, 2025 at 10:09 AM
Key ideas:
• #EmergentReasoning — provably, no external logic engine needed.
• #GeometricLens — lift weights to a probability measure & watch training as a Wasserstein gradient flow; messy SGD turns into clean geometry.
• #Compositionality — small rules snap into big ones. (3/n)
• #EmergentReasoning — provably, no external logic engine needed.
• #GeometricLens — lift weights to a probability measure & watch training as a Wasserstein gradient flow; messy SGD turns into clean geometry.
• #Compositionality — small rules snap into big ones. (3/n)
Why the hype? It gives a principled story for how discrete, symbolic #reasoning can emerge inside a vanilla neural net trained with plain gradients. Continuous weights ⇒ spontaneous symbolic rules. Mathy yet hopefully still readable (2/n).
June 30, 2025 at 10:09 AM
Why the hype? It gives a principled story for how discrete, symbolic #reasoning can emerge inside a vanilla neural net trained with plain gradients. Continuous weights ⇒ spontaneous symbolic rules. Mathy yet hopefully still readable (2/n).
aha thanks! So fast you are
June 30, 2025 at 9:50 AM
aha thanks! So fast you are