




Athiya Deviyani
@athiya.bsky.social
LTI PhD at CMU on evaluation and trustworthy ML/NLP, prev AI&CS Edinburgh University, Google, YouTube, Apple, Netflix. Views are personal 👩🏻💻🇮🇩
athiyadeviyani.github.io
athiyadeviyani.github.io
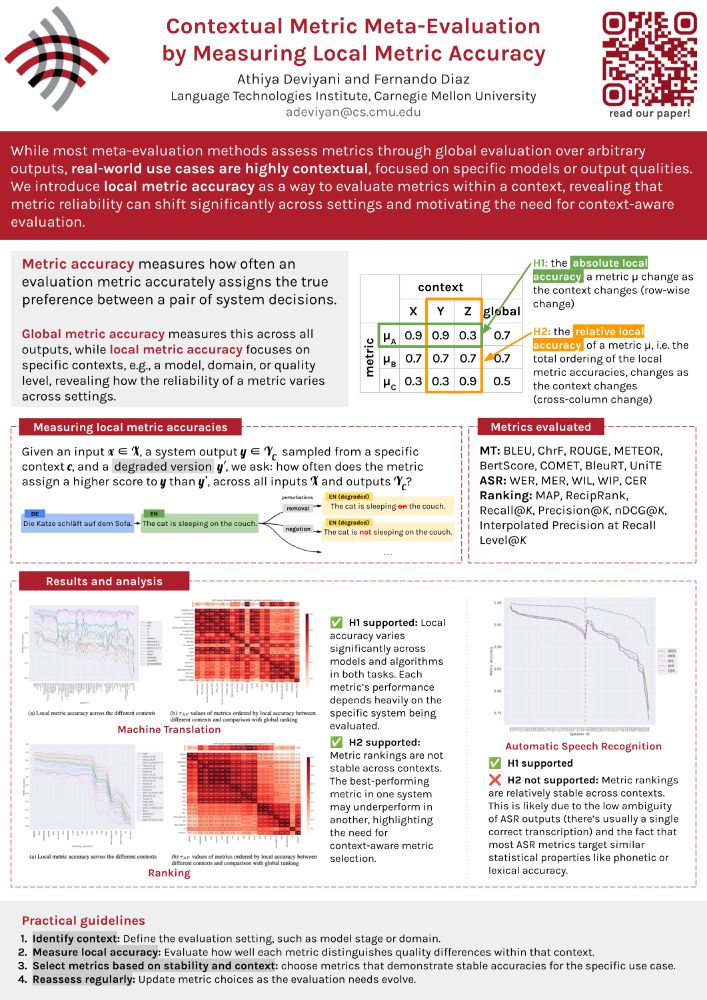
For ASR:
✅ H1 supported: Local accuracy still changes.
❌ H2 not supported: Metric rankings stay pretty stable.
This is probably because ASR outputs are less ambiguous, and metrics focus on similar properties, such as phonetic or lexical accuracy.
(🧵8/9)
✅ H1 supported: Local accuracy still changes.
❌ H2 not supported: Metric rankings stay pretty stable.
This is probably because ASR outputs are less ambiguous, and metrics focus on similar properties, such as phonetic or lexical accuracy.
(🧵8/9)

April 29, 2025 at 5:10 PM
For ASR:
✅ H1 supported: Local accuracy still changes.
❌ H2 not supported: Metric rankings stay pretty stable.
This is probably because ASR outputs are less ambiguous, and metrics focus on similar properties, such as phonetic or lexical accuracy.
(🧵8/9)
✅ H1 supported: Local accuracy still changes.
❌ H2 not supported: Metric rankings stay pretty stable.
This is probably because ASR outputs are less ambiguous, and metrics focus on similar properties, such as phonetic or lexical accuracy.
(🧵8/9)
Here’s what we found for MT and Ranking:
✅ H1 supported: Local accuracy varies a lot across systems and algorithms.
✅ H2 supported: Metric rankings shift between contexts.
🚨 Picking a metric based purely on global performance is risky!
Choose wisely. 🧙🏻♂️
(🧵7/9)
✅ H1 supported: Local accuracy varies a lot across systems and algorithms.
✅ H2 supported: Metric rankings shift between contexts.
🚨 Picking a metric based purely on global performance is risky!
Choose wisely. 🧙🏻♂️
(🧵7/9)


April 29, 2025 at 5:10 PM
Here’s what we found for MT and Ranking:
✅ H1 supported: Local accuracy varies a lot across systems and algorithms.
✅ H2 supported: Metric rankings shift between contexts.
🚨 Picking a metric based purely on global performance is risky!
Choose wisely. 🧙🏻♂️
(🧵7/9)
✅ H1 supported: Local accuracy varies a lot across systems and algorithms.
✅ H2 supported: Metric rankings shift between contexts.
🚨 Picking a metric based purely on global performance is risky!
Choose wisely. 🧙🏻♂️
(🧵7/9)
We evaluate this framework across three tasks:
📝 Machine Translation (MT)
🎙 Automatic Speech Recognition (ASR)
📈 Ranking
We cover popular metrics like BLEU, COMET, BERTScore, WER, METEOR, nDCG, and more!
(🧵6/9)
📝 Machine Translation (MT)
🎙 Automatic Speech Recognition (ASR)
📈 Ranking
We cover popular metrics like BLEU, COMET, BERTScore, WER, METEOR, nDCG, and more!
(🧵6/9)

April 29, 2025 at 5:10 PM
We evaluate this framework across three tasks:
📝 Machine Translation (MT)
🎙 Automatic Speech Recognition (ASR)
📈 Ranking
We cover popular metrics like BLEU, COMET, BERTScore, WER, METEOR, nDCG, and more!
(🧵6/9)
📝 Machine Translation (MT)
🎙 Automatic Speech Recognition (ASR)
📈 Ranking
We cover popular metrics like BLEU, COMET, BERTScore, WER, METEOR, nDCG, and more!
(🧵6/9)
We test two hypotheses:
🧪H1: The absolute local accuracy of a metric changes as the context changes
🧪H2: The relative local accuracy (how metrics rank against each other) also changes across contexts
(🧵5/9)
🧪H1: The absolute local accuracy of a metric changes as the context changes
🧪H2: The relative local accuracy (how metrics rank against each other) also changes across contexts
(🧵5/9)

April 29, 2025 at 5:10 PM
We test two hypotheses:
🧪H1: The absolute local accuracy of a metric changes as the context changes
🧪H2: The relative local accuracy (how metrics rank against each other) also changes across contexts
(🧵5/9)
🧪H1: The absolute local accuracy of a metric changes as the context changes
🧪H2: The relative local accuracy (how metrics rank against each other) also changes across contexts
(🧵5/9)
More formally: given an input x, an output y from a context c, and a degraded version y′, we ask: how often does the metric score y higher than y′ across all inputs in the context c?
We create y′ using perturbations that simulate realistic degradations automatically.
(🧵4/9)
We create y′ using perturbations that simulate realistic degradations automatically.
(🧵4/9)

April 29, 2025 at 5:10 PM
More formally: given an input x, an output y from a context c, and a degraded version y′, we ask: how often does the metric score y higher than y′ across all inputs in the context c?
We create y′ using perturbations that simulate realistic degradations automatically.
(🧵4/9)
We create y′ using perturbations that simulate realistic degradations automatically.
(🧵4/9)
🎯 Metric accuracy measures how often a metric picks the better system output.
🌍 Global accuracy averages this over all outputs.
🔎 Local accuracy zooms in on a specific context (like a model, domain, or quality level).
Contexts are just meaningful slices of your data.
(🧵3/9)
🌍 Global accuracy averages this over all outputs.
🔎 Local accuracy zooms in on a specific context (like a model, domain, or quality level).
Contexts are just meaningful slices of your data.
(🧵3/9)

April 29, 2025 at 5:10 PM
🎯 Metric accuracy measures how often a metric picks the better system output.
🌍 Global accuracy averages this over all outputs.
🔎 Local accuracy zooms in on a specific context (like a model, domain, or quality level).
Contexts are just meaningful slices of your data.
(🧵3/9)
🌍 Global accuracy averages this over all outputs.
🔎 Local accuracy zooms in on a specific context (like a model, domain, or quality level).
Contexts are just meaningful slices of your data.
(🧵3/9)
Ever trusted a metric that works great on average, only for it to fail in your specific use case?
In our #NAACL2025 paper (w/ @841io.bsky.social), we show why global evaluations are not enough and why context matters more than you think.
📄 aclanthology.org/2025.finding...
#NLP #Evaluation
(🧵1/9)
In our #NAACL2025 paper (w/ @841io.bsky.social), we show why global evaluations are not enough and why context matters more than you think.
📄 aclanthology.org/2025.finding...
#NLP #Evaluation
(🧵1/9)
April 29, 2025 at 5:10 PM
Ever trusted a metric that works great on average, only for it to fail in your specific use case?
In our #NAACL2025 paper (w/ @841io.bsky.social), we show why global evaluations are not enough and why context matters more than you think.
📄 aclanthology.org/2025.finding...
#NLP #Evaluation
(🧵1/9)
In our #NAACL2025 paper (w/ @841io.bsky.social), we show why global evaluations are not enough and why context matters more than you think.
📄 aclanthology.org/2025.finding...
#NLP #Evaluation
(🧵1/9)