


Apoorv Khandelwal
@apoorvkh.com

Curious how many papers were assigned to reviewers on average! Review quality seems better than average from my small sample size. Wondering if that correlates with a lower reviewer load? E.g. I only received 2 papers to review.
May 29, 2025 at 6:49 PM
Curious how many papers were assigned to reviewers on average! Review quality seems better than average from my small sample size. Wondering if that correlates with a lower reviewer load? E.g. I only received 2 papers to review.
+ No system pre-reqs, multi-stage PyTorch workflows in one script, CLI integrations, catching system failures as exceptions, SLURM support, better logging, and so much more!
Additional fine-tuning examples in our docs with:
@pytorch.org, Deepspeed, @lightningai.bsky.social, HF Accelerate
Additional fine-tuning examples in our docs with:
@pytorch.org, Deepspeed, @lightningai.bsky.social, HF Accelerate
March 11, 2025 at 4:54 PM
+ No system pre-reqs, multi-stage PyTorch workflows in one script, CLI integrations, catching system failures as exceptions, SLURM support, better logging, and so much more!
Additional fine-tuning examples in our docs with:
@pytorch.org, Deepspeed, @lightningai.bsky.social, HF Accelerate
Additional fine-tuning examples in our docs with:
@pytorch.org, Deepspeed, @lightningai.bsky.social, HF Accelerate
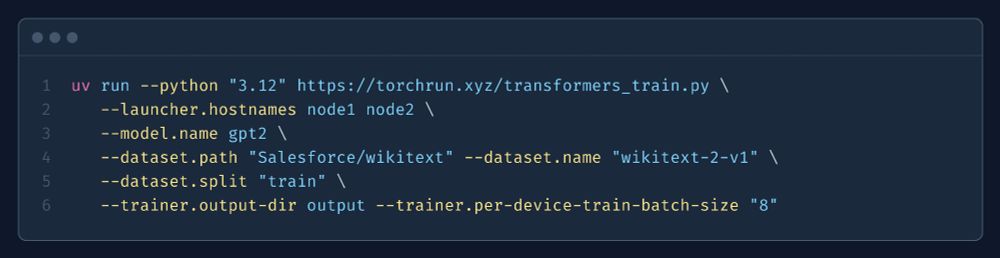
A cool side-effect: fine-tune any LLM (from
@huggingface
transformers) on any text dataset *with multiple nodes* in just *one command*.
torchrun.xyz/examples/tra...
@huggingface
transformers) on any text dataset *with multiple nodes* in just *one command*.
torchrun.xyz/examples/tra...
March 11, 2025 at 4:54 PM
A cool side-effect: fine-tune any LLM (from
@huggingface
transformers) on any text dataset *with multiple nodes* in just *one command*.
torchrun.xyz/examples/tra...
@huggingface
transformers) on any text dataset *with multiple nodes* in just *one command*.
torchrun.xyz/examples/tra...
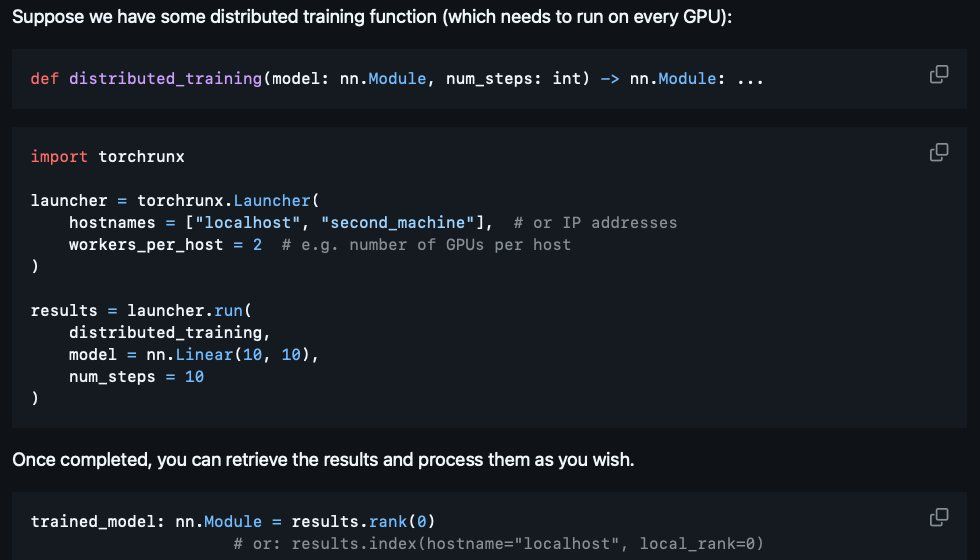
It's a replacement for CLI tools, like "torchrun".
Most basic usage: specify some (SSH-enabled) machines you want to parallelize your code on. Then launch a function onto that configuration.
All from inside your Python script!
Most basic usage: specify some (SSH-enabled) machines you want to parallelize your code on. Then launch a function onto that configuration.
All from inside your Python script!
March 11, 2025 at 4:54 PM
It's a replacement for CLI tools, like "torchrun".
Most basic usage: specify some (SSH-enabled) machines you want to parallelize your code on. Then launch a function onto that configuration.
All from inside your Python script!
Most basic usage: specify some (SSH-enabled) machines you want to parallelize your code on. Then launch a function onto that configuration.
All from inside your Python script!
I think typing my code and using a linter (ruff) + static type checker (pyright) saves me a lot of grief.
January 25, 2025 at 6:49 PM
I think typing my code and using a linter (ruff) + static type checker (pyright) saves me a lot of grief.
Reposted by Apoorv Khandelwal

Let he who hath not \usepackage[subtle]{savetrees}
December 18, 2024 at 1:27 AM
Let he who hath not \usepackage[subtle]{savetrees}
Reposted by Apoorv Khandelwal

I am an ex-Paperpile user and am liking Zotero lately! Free storage from the university helps.
November 27, 2024 at 5:15 AM
I am an ex-Paperpile user and am liking Zotero lately! Free storage from the university helps.
“Turn” a decoder into an encoder with LLM2Vec (github.com/McGill-NLP/l...). Seen at COLM 2024 :)
If you want the naive, training-free / model-agnostic approach: their related work section says it is most common to using the final token’s last hidden state.
If you want the naive, training-free / model-agnostic approach: their related work section says it is most common to using the final token’s last hidden state.

GitHub - McGill-NLP/llm2vec: Code for 'LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders'
Code for 'LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders' - McGill-NLP/llm2vec
github.com
November 26, 2024 at 1:37 AM
“Turn” a decoder into an encoder with LLM2Vec (github.com/McGill-NLP/l...). Seen at COLM 2024 :)
If you want the naive, training-free / model-agnostic approach: their related work section says it is most common to using the final token’s last hidden state.
If you want the naive, training-free / model-agnostic approach: their related work section says it is most common to using the final token’s last hidden state.
Thanks and great! Hope you are likewise doing well!
November 21, 2024 at 9:29 PM
Thanks and great! Hope you are likewise doing well!
Would be great to join, thanks!
November 21, 2024 at 9:15 PM
Would be great to join, thanks!