



Anthony Gitter
@anthonygitter.bsky.social
Computational biologist; Associate Prof. at University of Wisconsin-Madison; Jeanne M. Rowe Chair at Morgridge Institute
Something fun and sciencey is coming soon to Madison
November 14, 2025 at 5:20 PM
Something fun and sciencey is coming soon to Madison
The journal version of our Multi-omic Pathway Analysis of Cells (MPAC) software is now out: doi.org/10.1093/bioi...
MPAC uses biological pathway graphs to model DNA copy number and gene expression changes and infer activity states of all pathway members.
MPAC uses biological pathway graphs to model DNA copy number and gene expression changes and infer activity states of all pathway members.

October 10, 2025 at 2:56 PM
The journal version of our Multi-omic Pathway Analysis of Cells (MPAC) software is now out: doi.org/10.1093/bioi...
MPAC uses biological pathway graphs to model DNA copy number and gene expression changes and infer activity states of all pathway members.
MPAC uses biological pathway graphs to model DNA copy number and gene expression changes and infer activity states of all pathway members.
We can use METL for low-N protein design. We trained METL on Rosetta simulations of GFP biophysical attributes and only 64 experimental examples of GFP brightness. It designed fluorescent 5 and 10 mutants, including some with mutants entirely outside training set mutations. 7/

September 11, 2025 at 5:00 PM
We can use METL for low-N protein design. We trained METL on Rosetta simulations of GFP biophysical attributes and only 64 experimental examples of GFP brightness. It designed fluorescent 5 and 10 mutants, including some with mutants entirely outside training set mutations. 7/
A powerful aspect of pretraining on biophysical simulations is that the simulations can be customized to match the protein function and experimental assay. Our expanded simulations of the GB1-IgG complex with Rosetta InterfaceAnalyzer improve METL predictions of GB1 binding. 6/

September 11, 2025 at 5:00 PM
A powerful aspect of pretraining on biophysical simulations is that the simulations can be customized to match the protein function and experimental assay. Our expanded simulations of the GB1-IgG complex with Rosetta InterfaceAnalyzer improve METL predictions of GB1 binding. 6/
We also benchmark METL on four types of difficult extrapolation. For instance, positional extrapolation provides training data from some sequence positions and tests predictions at different sequence positions. Linear regression completely fails in this setting. 5/

September 11, 2025 at 5:00 PM
We also benchmark METL on four types of difficult extrapolation. For instance, positional extrapolation provides training data from some sequence positions and tests predictions at different sequence positions. Linear regression completely fails in this setting. 5/
We compare these approaches on deep mutational scanning datasets with increasing training set sizes. Biophysical pretraining helps METL generalize well with small training sets. However, augmented linear regression with EVE scores is great on some of these assays. 4/

September 11, 2025 at 5:00 PM
We compare these approaches on deep mutational scanning datasets with increasing training set sizes. Biophysical pretraining helps METL generalize well with small training sets. However, augmented linear regression with EVE scores is great on some of these assays. 4/
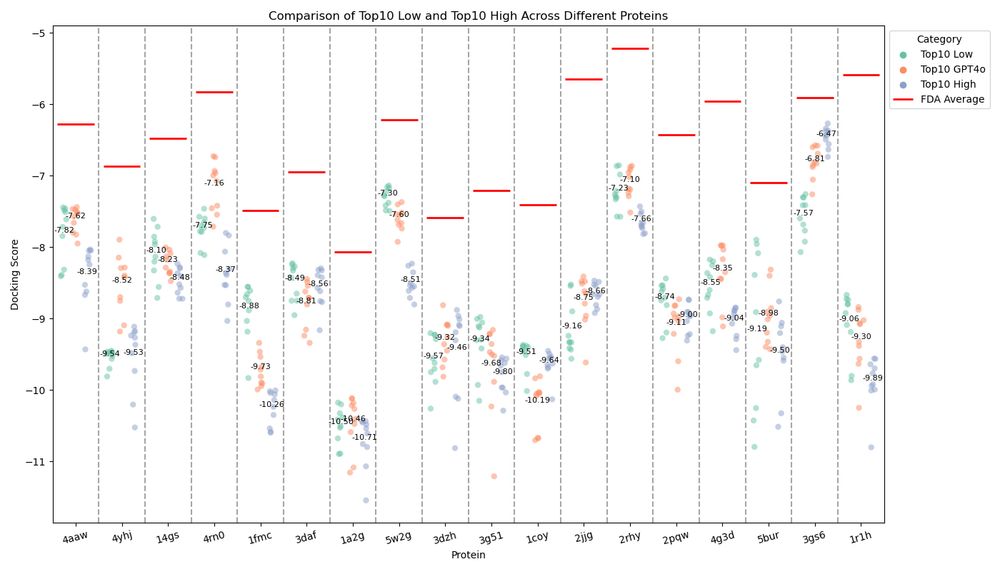
There are many more results and controls in the paper. Here's how the best (most negative) docking scores change when we use relevant assays, irrelevant assays, or no assays as context for generation with GPT-4o. In the majority of cases, but not all, relevant context helps. 6/
July 18, 2025 at 3:13 PM
There are many more results and controls in the paper. Here's how the best (most negative) docking scores change when we use relevant assays, irrelevant assays, or no assays as context for generation with GPT-4o. In the majority of cases, but not all, relevant context helps. 6/
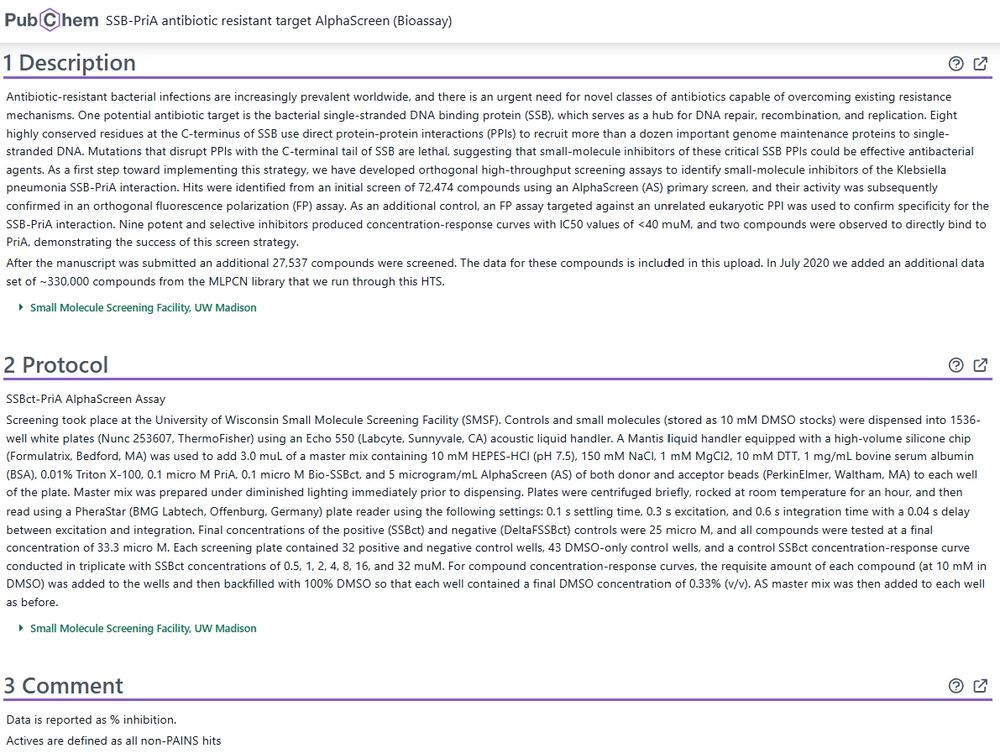
PubChem BioAssays can contain a lot of information about why and how an assay was run. Here's an example from our collaborators. pubchem.ncbi.nlm.nih.gov/bioassay/127...
There are now 1.7M PubChem BioAssays ranging in scale from a few tested molecules to high-throughput screens. 2/
There are now 1.7M PubChem BioAssays ranging in scale from a few tested molecules to high-throughput screens. 2/
July 18, 2025 at 3:13 PM
PubChem BioAssays can contain a lot of information about why and how an assay was run. Here's an example from our collaborators. pubchem.ncbi.nlm.nih.gov/bioassay/127...
There are now 1.7M PubChem BioAssays ranging in scale from a few tested molecules to high-throughput screens. 2/
There are now 1.7M PubChem BioAssays ranging in scale from a few tested molecules to high-throughput screens. 2/
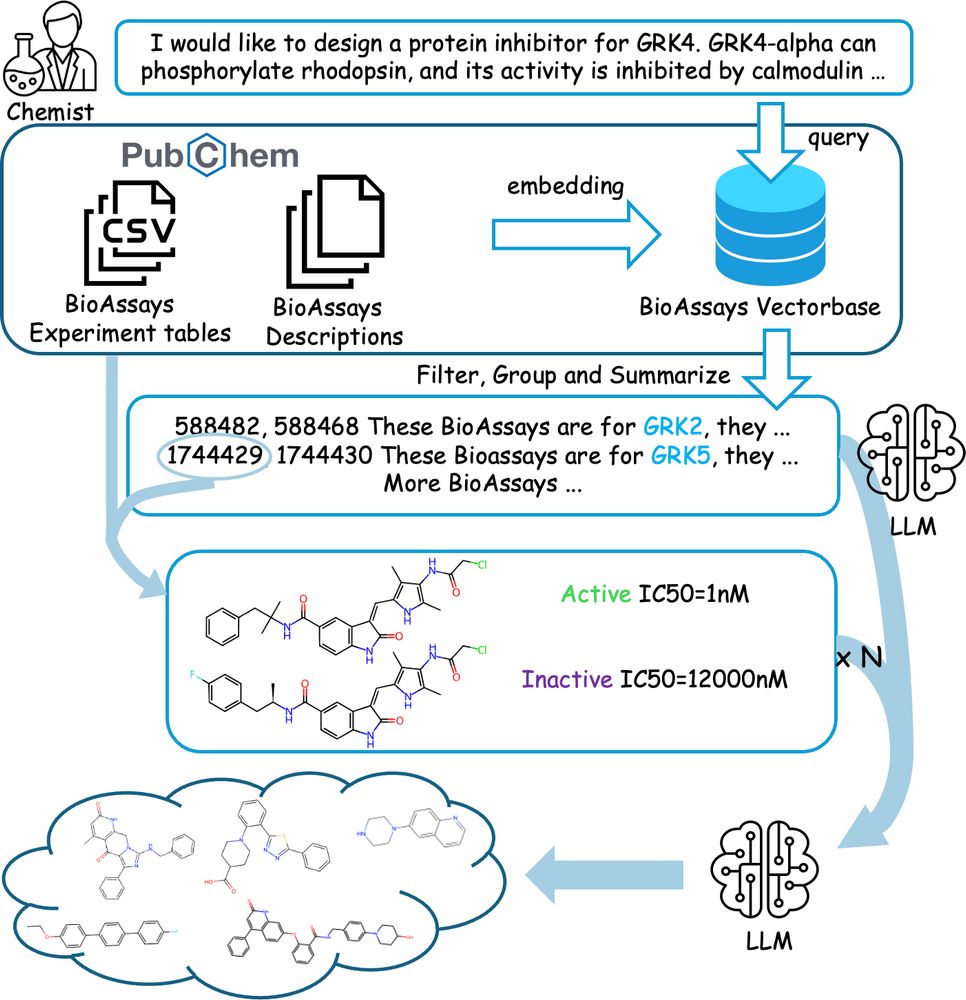
Our preprint Assay2Mol introduces uses PubChem chemical screening data as context when generating molecules with large language models. It uses assay descriptions and protocols to find relevant assays and that text plus active/inactive molecules as context for generation. 1/
July 18, 2025 at 3:13 PM
Our preprint Assay2Mol introduces uses PubChem chemical screening data as context when generating molecules with large language models. It uses assay descriptions and protocols to find relevant assays and that text plus active/inactive molecules as context for generation. 1/