




Annika Külpmann
@anniria.bsky.social
M. Sc. psychologist, PhD student (she/her)
interested in meta science, psychological research methods, measurement, open science, #rstats
interested in meta science, psychological research methods, measurement, open science, #rstats
Reposted by Annika Külpmann

"Runctitiononal features"? "Medical fymblal"? "1 Tol Line storee"? This gets worse the longer you look at it. But it's got to be good, because it was published in Nature Scientific Reports last week: www.nature.com/articles/s41... h/t @asa.tsbalans.se

November 27, 2025 at 9:30 AM
"Runctitiononal features"? "Medical fymblal"? "1 Tol Line storee"? This gets worse the longer you look at it. But it's got to be good, because it was published in Nature Scientific Reports last week: www.nature.com/articles/s41... h/t @asa.tsbalans.se
Reposted by Annika Külpmann

🚨 SynthNet is out 🚨
Researchers propose new constructs and measures faster than anyone can track. We (@anniria.bsky.social @ruben.the100.ci) built a search engine to check what already exists and help identify redundancies; indexing 74,000 scales from ~31,500 instruments in APA PsycTests. 🧵1/3
Researchers propose new constructs and measures faster than anyone can track. We (@anniria.bsky.social @ruben.the100.ci) built a search engine to check what already exists and help identify redundancies; indexing 74,000 scales from ~31,500 instruments in APA PsycTests. 🧵1/3
November 26, 2025 at 11:42 AM
🚨 SynthNet is out 🚨
Researchers propose new constructs and measures faster than anyone can track. We (@anniria.bsky.social @ruben.the100.ci) built a search engine to check what already exists and help identify redundancies; indexing 74,000 scales from ~31,500 instruments in APA PsycTests. 🧵1/3
Researchers propose new constructs and measures faster than anyone can track. We (@anniria.bsky.social @ruben.the100.ci) built a search engine to check what already exists and help identify redundancies; indexing 74,000 scales from ~31,500 instruments in APA PsycTests. 🧵1/3
Reposted by Annika Külpmann


Reposted by Annika Külpmann

There is no reason why systematic reviews can't be open. The data used for synthesis is *already* open and there are many excellent open source tools that can facilitate the easy sharing of analysis scripts.
Here's a nice guide for performing open systematic reviews doi.org/10.1525/coll...
Here's a nice guide for performing open systematic reviews doi.org/10.1525/coll...

November 24, 2025 at 12:10 PM
There is no reason why systematic reviews can't be open. The data used for synthesis is *already* open and there are many excellent open source tools that can facilitate the easy sharing of analysis scripts.
Here's a nice guide for performing open systematic reviews doi.org/10.1525/coll...
Here's a nice guide for performing open systematic reviews doi.org/10.1525/coll...
Reposted by Annika Külpmann
Yes, like a Netflix documentary included IN EVERY SOCIAL PSYCHOLOGY TEXTBOOK

I think many people don't realise that "When Prophecy Fails" is not an experimental study, but a work of history. Its like finding out that a popular Netflix documentary is fake. Bad but does not change science. Social psychology is not based on this book in any way.

There’s growing evidence that something was going seriously wrong in the classic early work on cognitive dissonance
Latest revelation: The story in When Prophecy Fails seems to have been fabricated in the most egregious way
But this is not the only one…
onlinelibrary.wiley.com/doi/abs/10.1...
Latest revelation: The story in When Prophecy Fails seems to have been fabricated in the most egregious way
But this is not the only one…
onlinelibrary.wiley.com/doi/abs/10.1...
November 13, 2025 at 4:11 PM
Yes, like a Netflix documentary included IN EVERY SOCIAL PSYCHOLOGY TEXTBOOK
Reposted by Annika Külpmann

We love a good 'association as as fluid' metaphor, but this guy takes it to the next level.
12/10 for the reminder that conditioning on a collider doesn't just mess with your identification; it can also flood your basement.
12/10 for the reminder that conditioning on a collider doesn't just mess with your identification; it can also flood your basement.
I built a DAG diagram with garden hoses for teaching.
Pictured: a collider bias diagram, inspired by a blocked pipe situation I experienced (which I credit with giving me the intuition though it also ruined my belongings in the flooded cellar).
Pictured: a collider bias diagram, inspired by a blocked pipe situation I experienced (which I credit with giving me the intuition though it also ruined my belongings in the flooded cellar).

October 31, 2025 at 9:47 AM
We love a good 'association as as fluid' metaphor, but this guy takes it to the next level.
12/10 for the reminder that conditioning on a collider doesn't just mess with your identification; it can also flood your basement.
12/10 for the reminder that conditioning on a collider doesn't just mess with your identification; it can also flood your basement.
Reposted by Annika Külpmann

There still seems to be a lot of confusion about significance testing in psych. No, p-values *don’t* become useless at large N. This flawed point also used to be framed as "too much power". But power isn't the problem – it's 1) unbalanced error rates and 2) the (lack of a) SESOI. 1/ >

But here's, the thing, p values and significance become useless at such large sample sizes. When you're dividing the coefficient by the SE and the sample size is in the tens of thousands, EVERYTHING IS SIGNIFICANT. All you're testing is whether the coefficient is different than zero.
October 31, 2025 at 8:13 AM
There still seems to be a lot of confusion about significance testing in psych. No, p-values *don’t* become useless at large N. This flawed point also used to be framed as "too much power". But power isn't the problem – it's 1) unbalanced error rates and 2) the (lack of a) SESOI. 1/ >
Reposted by Annika Külpmann

New hobby:
Remaking article abstracts as movie trailers to expose hype and fearmongering.
Remaking article abstracts as movie trailers to expose hype and fearmongering.
October 20, 2025 at 10:22 AM
New hobby:
Remaking article abstracts as movie trailers to expose hype and fearmongering.
Remaking article abstracts as movie trailers to expose hype and fearmongering.
Reposted by Annika Külpmann

I built a DAG diagram with garden hoses for teaching.
Pictured: a collider bias diagram, inspired by a blocked pipe situation I experienced (which I credit with giving me the intuition though it also ruined my belongings in the flooded cellar).
Pictured: a collider bias diagram, inspired by a blocked pipe situation I experienced (which I credit with giving me the intuition though it also ruined my belongings in the flooded cellar).
October 28, 2025 at 5:50 PM
I built a DAG diagram with garden hoses for teaching.
Pictured: a collider bias diagram, inspired by a blocked pipe situation I experienced (which I credit with giving me the intuition though it also ruined my belongings in the flooded cellar).
Pictured: a collider bias diagram, inspired by a blocked pipe situation I experienced (which I credit with giving me the intuition though it also ruined my belongings in the flooded cellar).
Reposted by Annika Külpmann

Major win for our field: finally a large, replicable effect.
Results of the replication are in!
Chocolate is more desirable than poop:
Cohen's d_rm = 6.20, 95%CI [5.63, 6.78]
N = 486, two single item 1-7 Likert scales of desirability.
w/
@jamiecummins.bsky.social
Chocolate is more desirable than poop:
Cohen's d_rm = 6.20, 95%CI [5.63, 6.78]
N = 486, two single item 1-7 Likert scales of desirability.
w/
@jamiecummins.bsky.social
Make an effect size prediction!
@jamiecummins.bsky.social and I are replicating Balcetis & Dunning's (2010) "chocolate is more desirable than poop" (Cohen's d = 4.52)
Let us known in the replies what effect size you think we'll find. Details of the study in the thread below.
@jamiecummins.bsky.social and I are replicating Balcetis & Dunning's (2010) "chocolate is more desirable than poop" (Cohen's d = 4.52)
Let us known in the replies what effect size you think we'll find. Details of the study in the thread below.
October 15, 2025 at 11:29 AM
Major win for our field: finally a large, replicable effect.
Reposted by Annika Külpmann

🚨 New preprint and online tool 🚨
Thrilled to share new work, mapping the 🗺️ landscape of behavioral reinforcement learning using an 🤖 LLM-powered bibliometric approach.
We built an online tool so you can explore the landscape yourself.
Online tool: mpib.berlin/vFVqU
Preprint: osf.io/6c2va_v1
Thrilled to share new work, mapping the 🗺️ landscape of behavioral reinforcement learning using an 🤖 LLM-powered bibliometric approach.
We built an online tool so you can explore the landscape yourself.
Online tool: mpib.berlin/vFVqU
Preprint: osf.io/6c2va_v1
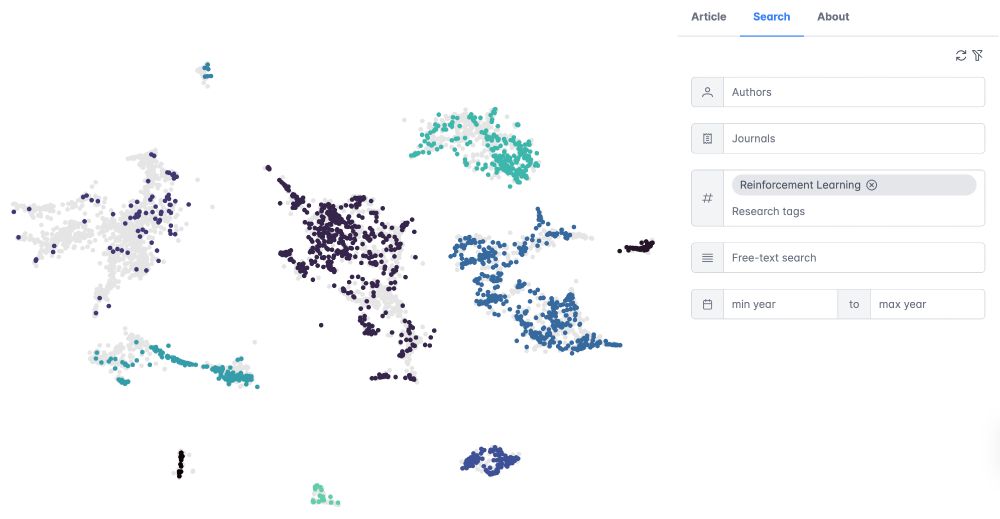
October 17, 2025 at 7:59 AM
🚨 New preprint and online tool 🚨
Thrilled to share new work, mapping the 🗺️ landscape of behavioral reinforcement learning using an 🤖 LLM-powered bibliometric approach.
We built an online tool so you can explore the landscape yourself.
Online tool: mpib.berlin/vFVqU
Preprint: osf.io/6c2va_v1
Thrilled to share new work, mapping the 🗺️ landscape of behavioral reinforcement learning using an 🤖 LLM-powered bibliometric approach.
We built an online tool so you can explore the landscape yourself.
Online tool: mpib.berlin/vFVqU
Preprint: osf.io/6c2va_v1
Reposted by Annika Külpmann
My article "Data is not available upon request" was published in Meta-Psychology. Very happy to see this out!
open.lnu.se/index.php/me...
open.lnu.se/index.php/me...
LnuOpen
| Meta-Psychology
open.lnu.se
October 4, 2025 at 12:54 PM
My article "Data is not available upon request" was published in Meta-Psychology. Very happy to see this out!
open.lnu.se/index.php/me...
open.lnu.se/index.php/me...
Reposted by Annika Külpmann
Make an effect size prediction!
@jamiecummins.bsky.social and I are replicating Balcetis & Dunning's (2010) "chocolate is more desirable than poop" (Cohen's d = 4.52)
Let us known in the replies what effect size you think we'll find. Details of the study in the thread below.
@jamiecummins.bsky.social and I are replicating Balcetis & Dunning's (2010) "chocolate is more desirable than poop" (Cohen's d = 4.52)
Let us known in the replies what effect size you think we'll find. Details of the study in the thread below.

October 13, 2025 at 11:30 AM
Make an effect size prediction!
@jamiecummins.bsky.social and I are replicating Balcetis & Dunning's (2010) "chocolate is more desirable than poop" (Cohen's d = 4.52)
Let us known in the replies what effect size you think we'll find. Details of the study in the thread below.
@jamiecummins.bsky.social and I are replicating Balcetis & Dunning's (2010) "chocolate is more desirable than poop" (Cohen's d = 4.52)
Let us known in the replies what effect size you think we'll find. Details of the study in the thread below.
Reposted by Annika Külpmann
Next up, @dirkwulff.bsky.social talks about conceptual clutter and jingle & jangle in psych #DPPD25

September 23, 2025 at 12:56 PM
Next up, @dirkwulff.bsky.social talks about conceptual clutter and jingle & jangle in psych #DPPD25
Reposted by Annika Külpmann
There are 90,000 measures in APA PsycTests, 43% of which are never referenced after initial publication.
@bjoernhommel.bsky.social talks about how correlations between items and scales can be predicted by LLMs, which may help keep construct proliferation at bay.
@bjoernhommel.bsky.social talks about how correlations between items and scales can be predicted by LLMs, which may help keep construct proliferation at bay.

September 23, 2025 at 12:39 PM
There are 90,000 measures in APA PsycTests, 43% of which are never referenced after initial publication.
@bjoernhommel.bsky.social talks about how correlations between items and scales can be predicted by LLMs, which may help keep construct proliferation at bay.
@bjoernhommel.bsky.social talks about how correlations between items and scales can be predicted by LLMs, which may help keep construct proliferation at bay.
Reposted by Annika Külpmann

Can large language models stand in for human participants?
Many social scientists seem to think so, and are already using "silicon samples" in research.
One problem: depending on the analytic decisions made, you can basically get these samples to show any effect you want.
THREAD 🧵
Many social scientists seem to think so, and are already using "silicon samples" in research.
One problem: depending on the analytic decisions made, you can basically get these samples to show any effect you want.
THREAD 🧵

The threat of analytic flexibility in using large language models to simulate human data: A call to attention
Social scientists are now using large language models to create "silicon samples" - synthetic datasets intended to stand in for human respondents, aimed at revolutionising human subjects research. How...
arxiv.org
September 18, 2025 at 7:56 AM
Can large language models stand in for human participants?
Many social scientists seem to think so, and are already using "silicon samples" in research.
One problem: depending on the analytic decisions made, you can basically get these samples to show any effect you want.
THREAD 🧵
Many social scientists seem to think so, and are already using "silicon samples" in research.
One problem: depending on the analytic decisions made, you can basically get these samples to show any effect you want.
THREAD 🧵
Reposted by Annika Külpmann
If you're going to #DPPD25 next week and would like to learn more about LLMs in Behavioral Science: One spot for my Workshop "Introduction to Large Language Modeling" (Kassel, next Sunday) just opened up. dppd2025.de/programm/pre...
Pre-Conference Workshops - DPPD 2025
Alle Pre-Conference Workshops finden am 21. September ab 9:00 Uhr statt (ganztägige Workshops). Die Workshops werden ab einer Mindestteilnehmendenzahl von 10 Personen durchgeführt. Die Höchstzahl […]
dppd2025.de
September 14, 2025 at 10:34 AM
If you're going to #DPPD25 next week and would like to learn more about LLMs in Behavioral Science: One spot for my Workshop "Introduction to Large Language Modeling" (Kassel, next Sunday) just opened up. dppd2025.de/programm/pre...
Reposted by Annika Külpmann

Another one of Stephan Schleim's critical account of biological psychiatry
scilogs.spektrum.de/menschen-bil...
scilogs.spektrum.de/menschen-bil...

Depression: Does psychotherapy make new nerve cells grow?
According to a study at the University of Halle-Wittenberg, the effect of psychotherapy has now been “medically and scientifically” proven
scilogs.spektrum.de
September 13, 2025 at 7:37 PM
Another one of Stephan Schleim's critical account of biological psychiatry
scilogs.spektrum.de/menschen-bil...
scilogs.spektrum.de/menschen-bil...
Reposted by Annika Külpmann

Unfortunately I just found out you can use Rayshader to make ggplots 3D.
This won't become a timesink for me at all, nope, I won't get distracted by this
This won't become a timesink for me at all, nope, I won't get distracted by this

September 2, 2025 at 10:26 PM
Unfortunately I just found out you can use Rayshader to make ggplots 3D.
This won't become a timesink for me at all, nope, I won't get distracted by this
This won't become a timesink for me at all, nope, I won't get distracted by this
Reposted by Annika Külpmann
Key claim of trimodal response to SSRI in the STAR*D trial is not computationally reproducible
www.sciencedirect.com/science/arti...
www.sciencedirect.com/science/arti...

Large responses to antidepressants or methodological artifacts? A secondary analysis of STAR*D, a single-arm, open-label, non-industry antidepressant trial
To replicate Stone et al.'s (2022) [1] finding that the distribution of response in clinical antidepressant trials is trimodal with large, medium-effe…
www.sciencedirect.com
August 27, 2025 at 7:04 AM
Key claim of trimodal response to SSRI in the STAR*D trial is not computationally reproducible
www.sciencedirect.com/science/arti...
www.sciencedirect.com/science/arti...
Reposted by Annika Külpmann
Did you know there's a package to reformat code to meet the {tidyverse} style guide?
{styler} is super useful for teaching students and helping them make their code more legible. It even has a drop down menu to do it with a point-and-click.
styler.r-lib.org
{styler} is super useful for teaching students and helping them make their code more legible. It even has a drop down menu to do it with a point-and-click.
styler.r-lib.org
August 23, 2025 at 4:16 PM
Did you know there's a package to reformat code to meet the {tidyverse} style guide?
{styler} is super useful for teaching students and helping them make their code more legible. It even has a drop down menu to do it with a point-and-click.
styler.r-lib.org
{styler} is super useful for teaching students and helping them make their code more legible. It even has a drop down menu to do it with a point-and-click.
styler.r-lib.org
Reposted by Annika Külpmann
Sustainability by numbers update on the carbon footprint of ChatGPT and Gemini!
I really appreciated that @hannahritchie.bsky.social is following the developments (and also distinguishes between individual-level impact vs. AI/data centers as a whole).
I really appreciated that @hannahritchie.bsky.social is following the developments (and also distinguishes between individual-level impact vs. AI/data centers as a whole).

What's the carbon footprint of using ChatGPT or Gemini? [August 2025 update]
A new study from Google suggests its Gemini LLM uses around 0.24 Wh per text query. That's the same energy as using a microwave for one second.
www.sustainabilitybynumbers.com
August 22, 2025 at 6:03 AM
Sustainability by numbers update on the carbon footprint of ChatGPT and Gemini!
I really appreciated that @hannahritchie.bsky.social is following the developments (and also distinguishes between individual-level impact vs. AI/data centers as a whole).
I really appreciated that @hannahritchie.bsky.social is following the developments (and also distinguishes between individual-level impact vs. AI/data centers as a whole).
Reposted by Annika Külpmann
I wrote an R package that creates standardized R project structures that are compliant with @mekline.bsky.social's psych-DS...ish.
It also creates additional features for reproducibility and teaching like a readme, license, .gitignore and Quarto templates
+ can validate existing projects
It also creates additional features for reproducibility and teaching like a readme, license, .gitignore and Quarto templates
+ can validate existing projects
Creating and validating standardized R project structures that are psych-DS compliant-ish
Making psychological code and data FAIR is hard, in part because different projects organize their code and data very differently.
Sometimes this is for good reasons, such as due to the demands of a g...
mmmdata.io
August 15, 2025 at 6:00 PM
I wrote an R package that creates standardized R project structures that are compliant with @mekline.bsky.social's psych-DS...ish.
It also creates additional features for reproducibility and teaching like a readme, license, .gitignore and Quarto templates
+ can validate existing projects
It also creates additional features for reproducibility and teaching like a readme, license, .gitignore and Quarto templates
+ can validate existing projects
Reposted by Annika Külpmann

they tried to explain mindfulness to me but i wasn’t paying attention
August 15, 2025 at 3:29 AM
they tried to explain mindfulness to me but i wasn’t paying attention
Reposted by Annika Külpmann

I disagree that it is a 'career strategy' at all. People are just science-ing. If you go into plumbing you can just plumb; you don't have to 'career.' But in science the culture may be one of careerism but not all humans connect with that. Some people like to just do good work.
August 15, 2025 at 12:39 PM
I disagree that it is a 'career strategy' at all. People are just science-ing. If you go into plumbing you can just plumb; you don't have to 'career.' But in science the culture may be one of careerism but not all humans connect with that. Some people like to just do good work.