



Ali Behrouz
@alibehrouz.bsky.social
Intern @Google, Ph.D. Student @Cornell_CS.
Interested in machine learning, LLM, brain, and healthcare.
abehrouz.github.io
Interested in machine learning, LLM, brain, and healthcare.
abehrouz.github.io
Paper: arxiv.org/pdf/2411.15671
arxiv.org
December 3, 2024 at 10:05 PM
Paper: arxiv.org/pdf/2411.15671
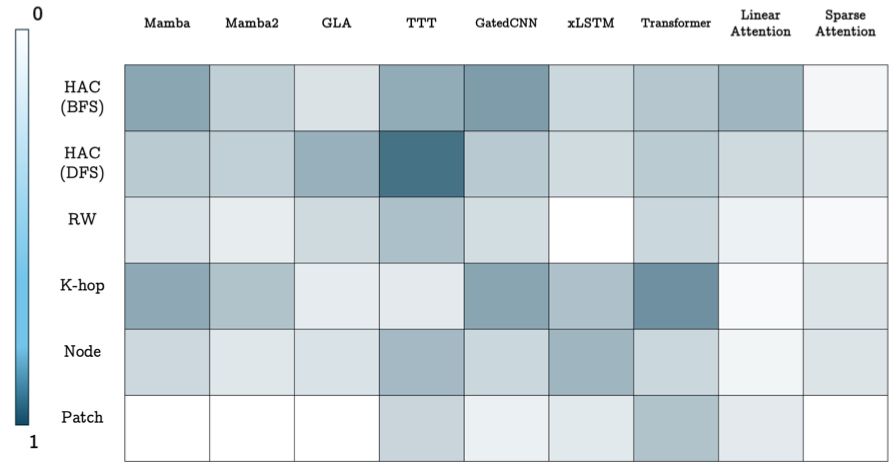
Are you interested in developing your own graph sequence model based on a specific sequence model? Stay tuned for the implementation of our framework that allows you to experiment with any combination of different sequence models and different tokenizations. Here is a sample of our results:
December 3, 2024 at 10:05 PM
Are you interested in developing your own graph sequence model based on a specific sequence model? Stay tuned for the implementation of our framework that allows you to experiment with any combination of different sequence models and different tokenizations. Here is a sample of our results:
What about hybrid models? We show that when combining recurrent models with Transformers, the model can be more efficient for some tasks:
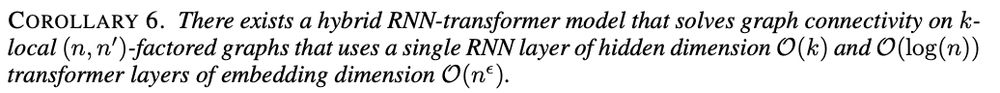
December 3, 2024 at 10:05 PM
What about hybrid models? We show that when combining recurrent models with Transformers, the model can be more efficient for some tasks:
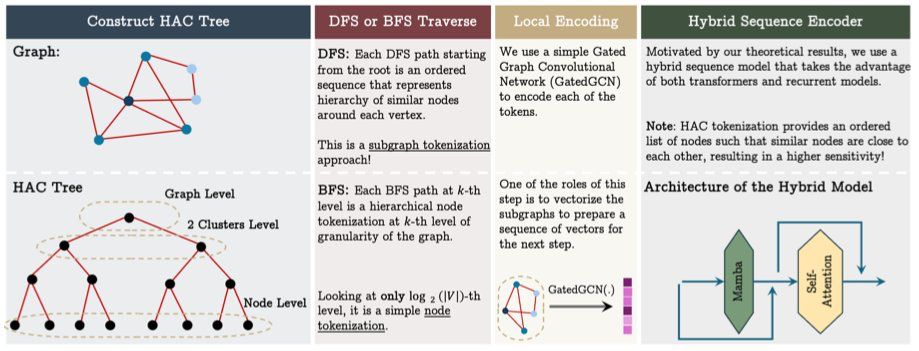
Finally, using HAC and what we learned from theoretical results, we present the GSM++ model that uses HAC to tokenize the graph, a GCN to encode local neighborhoods, and a hybrid architecture of SSM+Transformer for learning global dependencies.
December 3, 2024 at 10:04 PM
Finally, using HAC and what we learned from theoretical results, we present the GSM++ model that uses HAC to tokenize the graph, a GCN to encode local neighborhoods, and a hybrid architecture of SSM+Transformer for learning global dependencies.
Based on the linear sensitivity of linear RNNs, this means that using HAC, we have high sensitivity with relevant nodes and low sensitivity with irrelevant nodes.
December 3, 2024 at 10:04 PM
Based on the linear sensitivity of linear RNNs, this means that using HAC, we have high sensitivity with relevant nodes and low sensitivity with irrelevant nodes.
Interestingly, these results indicate that properly ordering nodes and losing permutation equivariant is not bad for some graph tasks. But how we can properly order nodes? We present a tokenization based on hierarchical affinity clustering (HAC) that puts highly dependent nodes close to each other.
December 3, 2024 at 10:04 PM
Interestingly, these results indicate that properly ordering nodes and losing permutation equivariant is not bad for some graph tasks. But how we can properly order nodes? We present a tokenization based on hierarchical affinity clustering (HAC) that puts highly dependent nodes close to each other.
What about connectivity tasks? Attempts to improve the quadratic cost with recurrent models result in a lack of parameter-efficient connectivity solutions. Again with proper ordering, recurrent models are efficient for these tasks! What is proper ordering? Graph needs to have a small node locality:
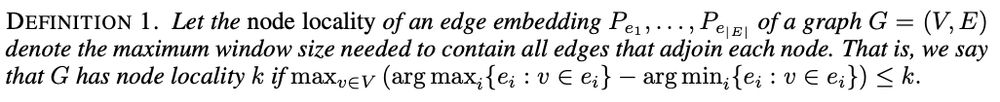
December 3, 2024 at 10:03 PM
What about connectivity tasks? Attempts to improve the quadratic cost with recurrent models result in a lack of parameter-efficient connectivity solutions. Again with proper ordering, recurrent models are efficient for these tasks! What is proper ordering? Graph needs to have a small node locality:
We motivate this by sensitivity of SSMs, which is linear with resp. to tokens’ distance: Similar to causal transformers, SSMs suffer from representational collapse when increasing the number of layers. So how can have a model that has good sensitivity but is robust to representational collapse?

December 3, 2024 at 10:01 PM
We motivate this by sensitivity of SSMs, which is linear with resp. to tokens’ distance: Similar to causal transformers, SSMs suffer from representational collapse when increasing the number of layers. So how can have a model that has good sensitivity but is robust to representational collapse?
This recurrent nature, however, is usually known as an undesirable property for graph tasks. We show that ordering nodes is not that bad for some graph tasks, and even by using proper ordering, you can improve the performance.
December 3, 2024 at 10:00 PM
This recurrent nature, however, is usually known as an undesirable property for graph tasks. We show that ordering nodes is not that bad for some graph tasks, and even by using proper ordering, you can improve the performance.
This framework allows us to answer: What Sequence Model is Right for Your Task? We realize that the answer to this depends on the type of the problem. For counting tasks, Transformers are unable to count without proper positional encoding, but we show that this is a simple task for recurrent models!
December 3, 2024 at 9:59 PM
This framework allows us to answer: What Sequence Model is Right for Your Task? We realize that the answer to this depends on the type of the problem. For counting tasks, Transformers are unable to count without proper positional encoding, but we show that this is a simple task for recurrent models!
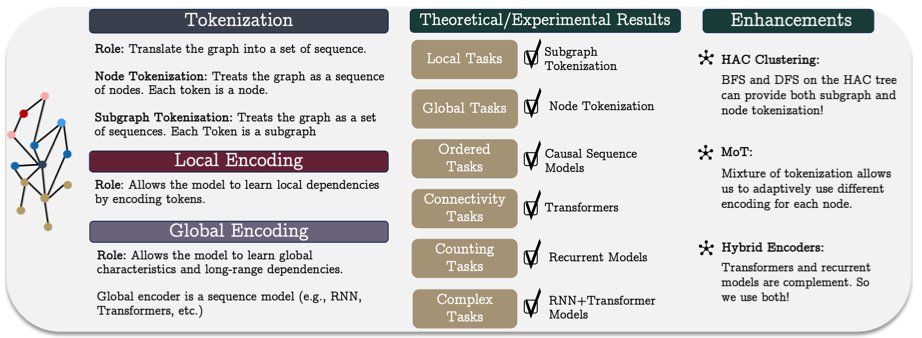
We present a simple framework that includes many existing graph sequence models based on three simple steps: (1) tokenize the graph into a set of sequences, (2) local encoding that encodes tokens, and (3) global encoding that uses a sequence model to learn long-range dependencies.
December 3, 2024 at 9:57 PM
We present a simple framework that includes many existing graph sequence models based on three simple steps: (1) tokenize the graph into a set of sequences, (2) local encoding that encodes tokens, and (3) global encoding that uses a sequence model to learn long-range dependencies.
The main focus of this paper was on time series data, but the inductive 2D bias in our selective 2D SSM is potentially useful for images, videos, and speech, avoiding using different scans.
Paper: openreview.net/forum?id=ncY...
Paper: openreview.net/forum?id=ncY...

Chimera: Effectively Modeling Multivariate Time Series with...
Modeling multivariate time series is a well-established problem with a wide range of applications from healthcare to financial markets. It, however, is challenging as it requires methods to (1)...
openreview.net
November 20, 2024 at 1:49 AM
The main focus of this paper was on time series data, but the inductive 2D bias in our selective 2D SSM is potentially useful for images, videos, and speech, avoiding using different scans.
Paper: openreview.net/forum?id=ncY...
Paper: openreview.net/forum?id=ncY...
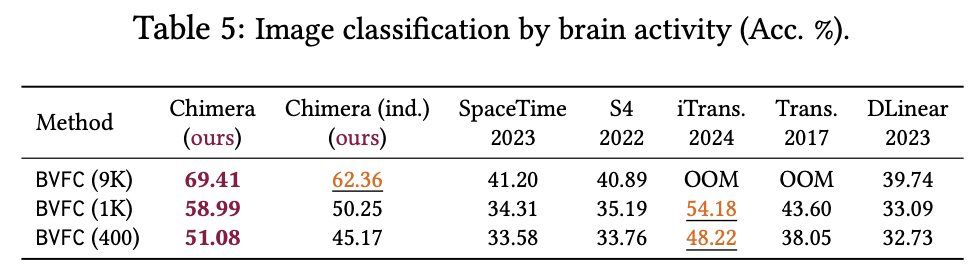
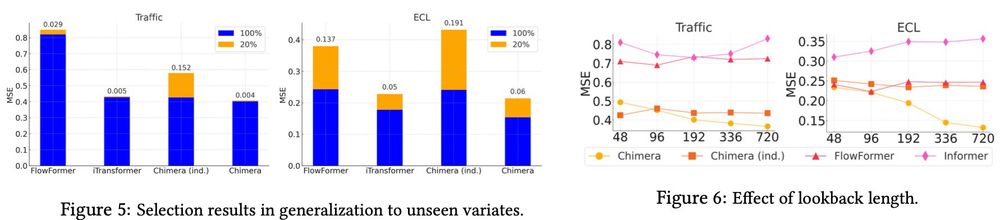
We show the importance of data-dependency in Chimera by a case study on image classification based on the brain response of a subject. We further show the selection mechanism in the S6 block and Mamba can be seen in Chimera but in both dimensions of time and variates: (7/8)
November 20, 2024 at 1:47 AM
We show the importance of data-dependency in Chimera by a case study on image classification based on the brain response of a subject. We further show the selection mechanism in the S6 block and Mamba can be seen in Chimera but in both dimensions of time and variates: (7/8)
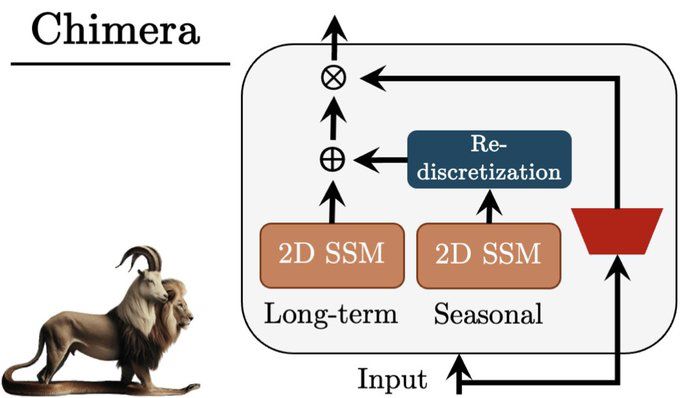
Using this 2D SSM, we present Chimera, a three-headed architecture that is capable of learning both long-term progression and seasonal patterns, using different discretization processes: (6/8)
November 20, 2024 at 1:46 AM
Using this 2D SSM, we present Chimera, a three-headed architecture that is capable of learning both long-term progression and seasonal patterns, using different discretization processes: (6/8)
We further discuss how S4ND-like extension of Mamba and Mamba-2 are the special cases of our 2D SSMs when restricting the transition matrices: (5/8)

November 20, 2024 at 1:46 AM
We further discuss how S4ND-like extension of Mamba and Mamba-2 are the special cases of our 2D SSMs when restricting the transition matrices: (5/8)
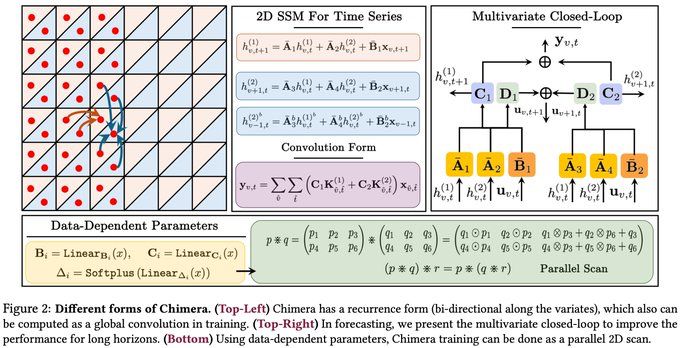
Similar to S6, to enhance the power of 2D SSM, we let its parameters be the function of the input, resulting in losing convolution form. We show this 2D recurrence can be done using a parallel 2D scan based on a new associative operator, resulting in fast parallelizable training.
November 20, 2024 at 1:45 AM
Similar to S6, to enhance the power of 2D SSM, we let its parameters be the function of the input, resulting in losing convolution form. We show this 2D recurrence can be done using a parallel 2D scan based on a new associative operator, resulting in fast parallelizable training.
Intuitively, the first and second hidden states carry information along the 'time' and 'variate' dimensions. A_2 and A_3 control how much information from the other dimension should be combined, providing full control of information flow from other variates, if are informative. (3/8)
November 20, 2024 at 1:44 AM
Intuitively, the first and second hidden states carry information along the 'time' and 'variate' dimensions. A_2 and A_3 control how much information from the other dimension should be combined, providing full control of information flow from other variates, if are informative. (3/8)
2D SSMs are based on linear Partial Differential Equation (PDE) with two variables (here are time and time series's variates). Using ZOH, we discretize the PDE, resulting in a 2D recurrence formula as follows: (2/8)

November 20, 2024 at 1:44 AM
2D SSMs are based on linear Partial Differential Equation (PDE) with two variables (here are time and time series's variates). Using ZOH, we discretize the PDE, resulting in a 2D recurrence formula as follows: (2/8)