



Antonino Greco
@agreco.bsky.social
Computational Cognitive Scientist 🧠🤖 • NeuroAI, Predictive Coding, RL & Deep Learning, Complex Systems • Postdoc at @siegellab.bsky.social, @unituebingen.bsky.social • Husband & Dad
🎓 https://scholar.google.com/citations?hl=en&user=k5eR8_oAAAAJ
🎓 https://scholar.google.com/citations?hl=en&user=k5eR8_oAAAAJ
These findings uncover a dual mechanism for robust sensory coding, with neural stochasticity (dropout) preventing unit-level co-adaptation and top-down feedback harnessing high-level information to stabilize model activity on compact low-dimensional manifolds

August 18, 2025 at 11:18 AM
These findings uncover a dual mechanism for robust sensory coding, with neural stochasticity (dropout) preventing unit-level co-adaptation and top-down feedback harnessing high-level information to stabilize model activity on compact low-dimensional manifolds
To elucidate the reasons of such results, we estimated the intrinsic dimensionality of the latent manifold underlying the bottom-up, top-down and information integration streams
We found only feedback+dropout constrained model activity on low dimensional manifolds!
We found only feedback+dropout constrained model activity on low dimensional manifolds!

August 18, 2025 at 11:18 AM
To elucidate the reasons of such results, we estimated the intrinsic dimensionality of the latent manifold underlying the bottom-up, top-down and information integration streams
We found only feedback+dropout constrained model activity on low dimensional manifolds!
We found only feedback+dropout constrained model activity on low dimensional manifolds!
We evaluate these models (10 instances each model class) on noise perturbation and adversarial attacks with increasing strength.
Crucially, only models with both top-down feedback and dropout (dark blue 👇) outperformed all other models on sensory robustness
Crucially, only models with both top-down feedback and dropout (dark blue 👇) outperformed all other models on sensory robustness

August 18, 2025 at 11:18 AM
We evaluate these models (10 instances each model class) on noise perturbation and adversarial attacks with increasing strength.
Crucially, only models with both top-down feedback and dropout (dark blue 👇) outperformed all other models on sensory robustness
Crucially, only models with both top-down feedback and dropout (dark blue 👇) outperformed all other models on sensory robustness
To integrate bottom-up (feedforward pass) and top-down (feedback projection) information, we used a learnable fusion mechanism that concatenate feature maps from both streams and process them jointly through a convolutional layer.

August 18, 2025 at 11:18 AM
To integrate bottom-up (feedforward pass) and top-down (feedback projection) information, we used a learnable fusion mechanism that concatenate feature maps from both streams and process them jointly through a convolutional layer.
We trained ConvRNNs for image classification on the CIFAR-10 dataset manipulating 2 factors (4 model classes):
🔹 Feedback connections (present / absent)
🔵 Dropout (present / absent during training)
Models had 3 layers, 10 time steps, with 1 long-range feedback connection from last to first layer
🔹 Feedback connections (present / absent)
🔵 Dropout (present / absent during training)
Models had 3 layers, 10 time steps, with 1 long-range feedback connection from last to first layer

August 18, 2025 at 11:18 AM
We trained ConvRNNs for image classification on the CIFAR-10 dataset manipulating 2 factors (4 model classes):
🔹 Feedback connections (present / absent)
🔵 Dropout (present / absent during training)
Models had 3 layers, 10 time steps, with 1 long-range feedback connection from last to first layer
🔹 Feedback connections (present / absent)
🔵 Dropout (present / absent during training)
Models had 3 layers, 10 time steps, with 1 long-range feedback connection from last to first layer
However, these studies most often compare feedforward models against architectures that combine 2 types of connections:
➡️ recurrent (lateral), reinjecting layer’s previous hidden state
↘️ feedback, projecting from higher to lower layers
leaving the individual roles of each pathway unclear
➡️ recurrent (lateral), reinjecting layer’s previous hidden state
↘️ feedback, projecting from higher to lower layers
leaving the individual roles of each pathway unclear

August 18, 2025 at 11:18 AM
However, these studies most often compare feedforward models against architectures that combine 2 types of connections:
➡️ recurrent (lateral), reinjecting layer’s previous hidden state
↘️ feedback, projecting from higher to lower layers
leaving the individual roles of each pathway unclear
➡️ recurrent (lateral), reinjecting layer’s previous hidden state
↘️ feedback, projecting from higher to lower layers
leaving the individual roles of each pathway unclear
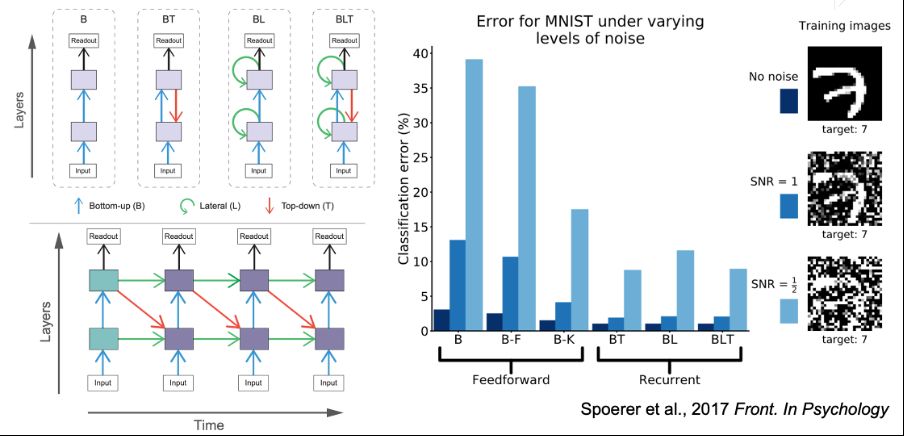
A growing body of work has demonstrated that recurrent vision architectures, typically implemented as convolutional recurrent neural networks (ConvRNNs), outperform purely feedforward CNNs on out-of-distribution (OOD) challenges such as occlusion, noise perturbation, and adversarial attacks
August 18, 2025 at 11:18 AM
A growing body of work has demonstrated that recurrent vision architectures, typically implemented as convolutional recurrent neural networks (ConvRNNs), outperform purely feedforward CNNs on out-of-distribution (OOD) challenges such as occlusion, noise perturbation, and adversarial attacks
Are top-down feedback connections enough for robust vision?
We found ConvRNN with top-down feedback exhibiting OOD robustness only when trained with dropout, revealing a dual mechanism for robust sensory coding
with @marco-d.bsky.social, Karl Friston, Giovanni Pezzulo & @siegellab.bsky.social
🧵👇
We found ConvRNN with top-down feedback exhibiting OOD robustness only when trained with dropout, revealing a dual mechanism for robust sensory coding
with @marco-d.bsky.social, Karl Friston, Giovanni Pezzulo & @siegellab.bsky.social
🧵👇

August 18, 2025 at 11:18 AM
Are top-down feedback connections enough for robust vision?
We found ConvRNN with top-down feedback exhibiting OOD robustness only when trained with dropout, revealing a dual mechanism for robust sensory coding
with @marco-d.bsky.social, Karl Friston, Giovanni Pezzulo & @siegellab.bsky.social
🧵👇
We found ConvRNN with top-down feedback exhibiting OOD robustness only when trained with dropout, revealing a dual mechanism for robust sensory coding
with @marco-d.bsky.social, Karl Friston, Giovanni Pezzulo & @siegellab.bsky.social
🧵👇
We speculate that evolutionary pressures may have favored sensory systems with a more distributed reliance on multiple features, as it confers robustness in unusual environments, even if it occasionally sacrifices peak performance under ordinary circumstances

August 9, 2025 at 11:04 AM
We speculate that evolutionary pressures may have favored sensory systems with a more distributed reliance on multiple features, as it confers robustness in unusual environments, even if it occasionally sacrifices peak performance under ordinary circumstances
We argue that the discrepancies between humans and DNNs provide profound insights into the computational mechanisms underlying spatial hearing. The lack of robustness observed in these models likely stems from their tendency to prioritize simple features, aka the “simplicity bias”

August 9, 2025 at 11:04 AM
We argue that the discrepancies between humans and DNNs provide profound insights into the computational mechanisms underlying spatial hearing. The lack of robustness observed in these models likely stems from their tendency to prioritize simple features, aka the “simplicity bias”
We also ran a second experiment to dissect these third feats, by matching the power and phase of these defeat. sounds across ears. We found that humans were also robust to both power and phase defeat, while DNN models significanlty dropped their performance.

August 9, 2025 at 11:04 AM
We also ran a second experiment to dissect these third feats, by matching the power and phase of these defeat. sounds across ears. We found that humans were also robust to both power and phase defeat, while DNN models significanlty dropped their performance.
To sum up these results, we correlate their response pattern (transfer function) with the ideal performance, finding that humans mantained a robust performance across all conditions, with an average corr of .94 ❗️ against the .77 and .68 of Sim-trained and Finetuned models

August 9, 2025 at 11:04 AM
To sum up these results, we correlate their response pattern (transfer function) with the ideal performance, finding that humans mantained a robust performance across all conditions, with an average corr of .94 ❗️ against the .77 and .68 of Sim-trained and Finetuned models
Even by finetuning these models on our recorded sounds (not used in the evaluation), the alignment (encoding models) between humans and DNN model responses was pretty low on OOD defeat. stimuli, far from the noise ceiling

August 9, 2025 at 11:04 AM
Even by finetuning these models on our recorded sounds (not used in the evaluation), the alignment (encoding models) between humans and DNN model responses was pretty low on OOD defeat. stimuli, far from the noise ceiling
Importantly, we found that DNN models replicated human performance on in-training distribution stimuli (aka natural with ITD, ILD and 3rd feats), but they were much worse than humans on OOD stimuli! Especially in the defeat. stimuli with no primary interaural cues 👇

August 9, 2025 at 11:04 AM
Importantly, we found that DNN models replicated human performance on in-training distribution stimuli (aka natural with ITD, ILD and 3rd feats), but they were much worse than humans on OOD stimuli! Especially in the defeat. stimuli with no primary interaural cues 👇
Next, we turn to deep neural networks optimized for sound localization. We used pretrained models from this seminal work 👉 www.nature.com/articles/s41..., and probed these networks with our stimuli.
👇 model representations for natural, synth, and defeat. stimuli
👇 model representations for natural, synth, and defeat. stimuli

August 9, 2025 at 11:04 AM
Next, we turn to deep neural networks optimized for sound localization. We used pretrained models from this seminal work 👉 www.nature.com/articles/s41..., and probed these networks with our stimuli.
👇 model representations for natural, synth, and defeat. stimuli
👇 model representations for natural, synth, and defeat. stimuli
Crucially, we checked whether defeaturized stimuli lead to chance performance and found that humans preserved a pretty accurate localization ability!
👇 human responses in the natural, synth and “out-of-distribution” (defeat.) case, where the response pattern is not random
👇 human responses in the natural, synth and “out-of-distribution” (defeat.) case, where the response pattern is not random

August 9, 2025 at 11:04 AM
Crucially, we checked whether defeaturized stimuli lead to chance performance and found that humans preserved a pretty accurate localization ability!
👇 human responses in the natural, synth and “out-of-distribution” (defeat.) case, where the response pattern is not random
👇 human responses in the natural, synth and “out-of-distribution” (defeat.) case, where the response pattern is not random
We tested human listeners on these stimuli, checking their error (MAE) and transfer function. We found that natural behavior could be substantially recovered by synthesizing ITD & ILD, and defeaturized ITD & ILD (third feats only) had the worst performance.

August 9, 2025 at 11:04 AM
We tested human listeners on these stimuli, checking their error (MAE) and transfer function. We found that natural behavior could be substantially recovered by synthesizing ITD & ILD, and defeaturized ITD & ILD (third feats only) had the worst performance.
Natural stimuli comprised ✅ITD, ✅ILD and ✅“third features” (all other acoustic feats that are not ITD or ILD, spectral features)
Synthesized (ITD & ILD) stimuli had ✅ITD, ✅ILD but not ❌third features
Defeaturized (ITD & ILD) stimuli had ✅third features but not ❌ITD, ❌ILD
Synthesized (ITD & ILD) stimuli had ✅ITD, ✅ILD but not ❌third features
Defeaturized (ITD & ILD) stimuli had ✅third features but not ❌ITD, ❌ILD

August 9, 2025 at 11:04 AM
Natural stimuli comprised ✅ITD, ✅ILD and ✅“third features” (all other acoustic feats that are not ITD or ILD, spectral features)
Synthesized (ITD & ILD) stimuli had ✅ITD, ✅ILD but not ❌third features
Defeaturized (ITD & ILD) stimuli had ✅third features but not ❌ITD, ❌ILD
Synthesized (ITD & ILD) stimuli had ✅ITD, ✅ILD but not ❌third features
Defeaturized (ITD & ILD) stimuli had ✅third features but not ❌ITD, ❌ILD
In addition, we also generated artificial sounds by selectively including or excluding ITD and ILD cues.
Synthesized stimuli were generated by adding these cues to monaural sounds
Defeaturized stimuli were generated by subtracting these cues from the recorded sounds
Synthesized stimuli were generated by adding these cues to monaural sounds
Defeaturized stimuli were generated by subtracting these cues from the recorded sounds

August 9, 2025 at 11:04 AM
In addition, we also generated artificial sounds by selectively including or excluding ITD and ILD cues.
Synthesized stimuli were generated by adding these cues to monaural sounds
Defeaturized stimuli were generated by subtracting these cues from the recorded sounds
Synthesized stimuli were generated by adding these cues to monaural sounds
Defeaturized stimuli were generated by subtracting these cues from the recorded sounds
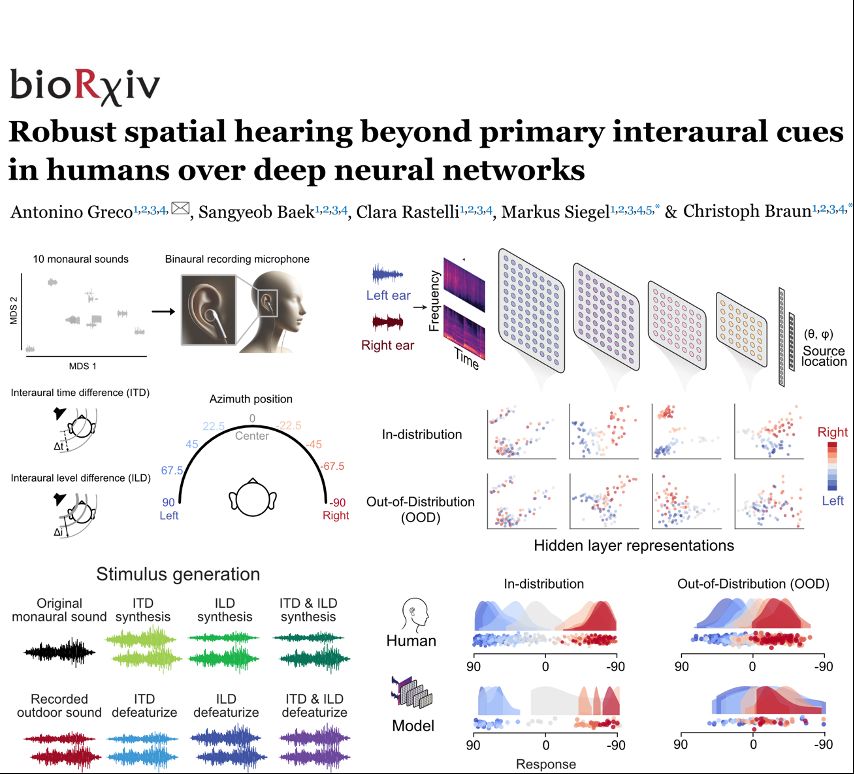
To address this, we collected a spatial sound dataset to test humans and DNNs on spatial hearing across the azimuth plane on 3 acoustic environments, 9 positions and 10 natural sounds. Primary interuaral cues, ITD and ILD, were aligned to the sound source position

August 9, 2025 at 11:04 AM
To address this, we collected a spatial sound dataset to test humans and DNNs on spatial hearing across the azimuth plane on 3 acoustic environments, 9 positions and 10 natural sounds. Primary interuaral cues, ITD and ILD, were aligned to the sound source position
Sound localization is assumed to rely on interaural time (ITD) and level (ILD) differences as primary interaural cues, but the contribution of additional auditory features remains unclear. So the question is, are ITD and ILD all you need for spatial hearing?

August 9, 2025 at 11:04 AM
Sound localization is assumed to rely on interaural time (ITD) and level (ILD) differences as primary interaural cues, but the contribution of additional auditory features remains unclear. So the question is, are ITD and ILD all you need for spatial hearing?
🔵 Proud to share our new preprint 🔵
We compared humans and deep neural networks on sound localization 👂📍
Humans robustly localized OOD sounds even without primary interaural cues (ITD & ILD)
Models localized well only in-training distribution sounds, failing on OOD regime
Link & full story 🧵👇
We compared humans and deep neural networks on sound localization 👂📍
Humans robustly localized OOD sounds even without primary interaural cues (ITD & ILD)
Models localized well only in-training distribution sounds, failing on OOD regime
Link & full story 🧵👇
August 9, 2025 at 11:04 AM
🔵 Proud to share our new preprint 🔵
We compared humans and deep neural networks on sound localization 👂📍
Humans robustly localized OOD sounds even without primary interaural cues (ITD & ILD)
Models localized well only in-training distribution sounds, failing on OOD regime
Link & full story 🧵👇
We compared humans and deep neural networks on sound localization 👂📍
Humans robustly localized OOD sounds even without primary interaural cues (ITD & ILD)
Models localized well only in-training distribution sounds, failing on OOD regime
Link & full story 🧵👇
cool paper on the limits of (naïve) foundation models!
it's always been and always will be about OOD generalization, probably the unifying problem that defines if a system is intelligent or not
The key question is, what inductive bias do you use to solve this task?
👇
arxiv.org/abs/2507.06952
it's always been and always will be about OOD generalization, probably the unifying problem that defines if a system is intelligent or not
The key question is, what inductive bias do you use to solve this task?
👇
arxiv.org/abs/2507.06952
July 12, 2025 at 8:50 PM
cool paper on the limits of (naïve) foundation models!
it's always been and always will be about OOD generalization, probably the unifying problem that defines if a system is intelligent or not
The key question is, what inductive bias do you use to solve this task?
👇
arxiv.org/abs/2507.06952
it's always been and always will be about OOD generalization, probably the unifying problem that defines if a system is intelligent or not
The key question is, what inductive bias do you use to solve this task?
👇
arxiv.org/abs/2507.06952
"Cognitive modeling using artificial intelligence" 👇
"We argue here that the most exciting of these is the use of AI models as cognitive models
[...]
Such cognitive models constitute a substantial advance that can inform theories of human intelligence"
#neuroAI
"We argue here that the most exciting of these is the use of AI models as cognitive models
[...]
Such cognitive models constitute a substantial advance that can inform theories of human intelligence"
#neuroAI

July 8, 2025 at 8:09 AM
"Cognitive modeling using artificial intelligence" 👇
"We argue here that the most exciting of these is the use of AI models as cognitive models
[...]
Such cognitive models constitute a substantial advance that can inform theories of human intelligence"
#neuroAI
"We argue here that the most exciting of these is the use of AI models as cognitive models
[...]
Such cognitive models constitute a substantial advance that can inform theories of human intelligence"
#neuroAI
Finally, we found that these prediction and errors were actually event-specific and not just at the sensory modality-level, while we also found that these incidental associations generalized beyond stimulus-stimulus pairings to encompass broader sensory events, including the absence of stimulation

May 18, 2025 at 12:16 PM
Finally, we found that these prediction and errors were actually event-specific and not just at the sensory modality-level, while we also found that these incidental associations generalized beyond stimulus-stimulus pairings to encompass broader sensory events, including the absence of stimulation