



@saganite.bsky.social
llm tinkerer. entropy cowboy. iconoclast.
I would like to share some work we've been doing at cascadetech.ai: Predicted Outputs in vLLM. If you aren't familiar with PO, it allows you to dramatically speed up generation when you know something about the contents of the output (think: code modification).

October 10, 2025 at 6:11 PM
I would like to share some work we've been doing at cascadetech.ai: Predicted Outputs in vLLM. If you aren't familiar with PO, it allows you to dramatically speed up generation when you know something about the contents of the output (think: code modification).
The window of human history where people know how to program computers is so vanishingly small. It only really began in earnest in the 60s. I learned in the 80s. The people learning today are probably some of the last humans to ever learn.
April 24, 2025 at 9:20 AM
The window of human history where people know how to program computers is so vanishingly small. It only really began in earnest in the 60s. I learned in the 80s. The people learning today are probably some of the last humans to ever learn.
@charles-irl.bsky.social are the modal api docs available anywhere as a machine readable markdown file? if they are i can't find it.
March 20, 2025 at 8:46 AM
@charles-irl.bsky.social are the modal api docs available anywhere as a machine readable markdown file? if they are i can't find it.
I'm not sure who needs to hear this, but I think it's worth taking note of the REALITY of the relationship between bsky and ai training data.
The fact of the matter is that THIS SKEET will certainly be part of many, many AI training runs, and there is nothing I nor anyone else can do to stop it.
The fact of the matter is that THIS SKEET will certainly be part of many, many AI training runs, and there is nothing I nor anyone else can do to stop it.
November 28, 2024 at 7:28 AM
I'm not sure who needs to hear this, but I think it's worth taking note of the REALITY of the relationship between bsky and ai training data.
The fact of the matter is that THIS SKEET will certainly be part of many, many AI training runs, and there is nothing I nor anyone else can do to stop it.
The fact of the matter is that THIS SKEET will certainly be part of many, many AI training runs, and there is nothing I nor anyone else can do to stop it.
Reposted

A blindspot for AI reasoning engines like o1 is that they all appear to be trained on very traditional deductive problem solving for chain of thought
What would a model trained on induction or abduction do? What about one trained on free association? Expert heuristics? Randomized exquisite corpse?
What would a model trained on induction or abduction do? What about one trained on free association? Expert heuristics? Randomized exquisite corpse?



November 26, 2024 at 2:38 AM
A blindspot for AI reasoning engines like o1 is that they all appear to be trained on very traditional deductive problem solving for chain of thought
What would a model trained on induction or abduction do? What about one trained on free association? Expert heuristics? Randomized exquisite corpse?
What would a model trained on induction or abduction do? What about one trained on free association? Expert heuristics? Randomized exquisite corpse?
Really loving bsky but if there is one place where the experience could be improved imo, it would be the Discover feed. I've spent a decent amount of time curating my preferences there, but I still see a lot of stuff that isn't at all relevant to my interests.
November 25, 2024 at 1:47 PM
Really loving bsky but if there is one place where the experience could be improved imo, it would be the Discover feed. I've spent a decent amount of time curating my preferences there, but I still see a lot of stuff that isn't at all relevant to my interests.
What a gift to the community, this is going to contribute so much to the future of open source models. Nice work team. 🙌

I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.
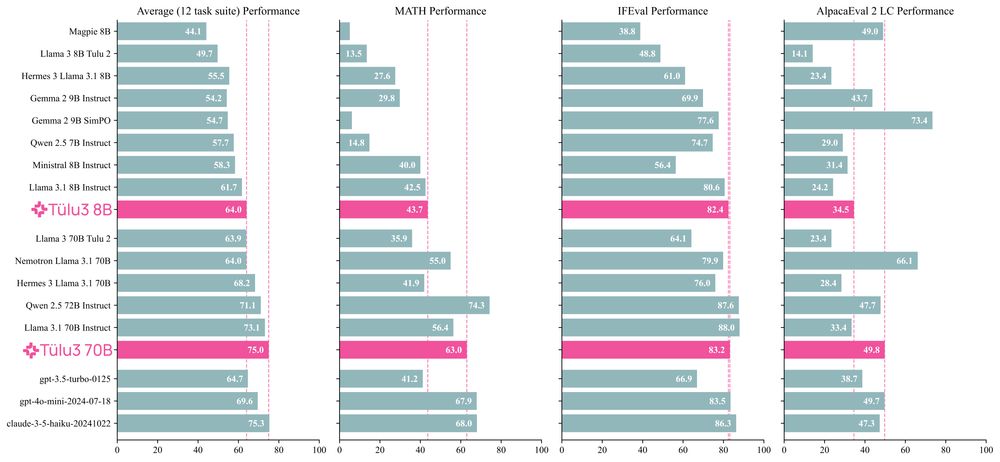
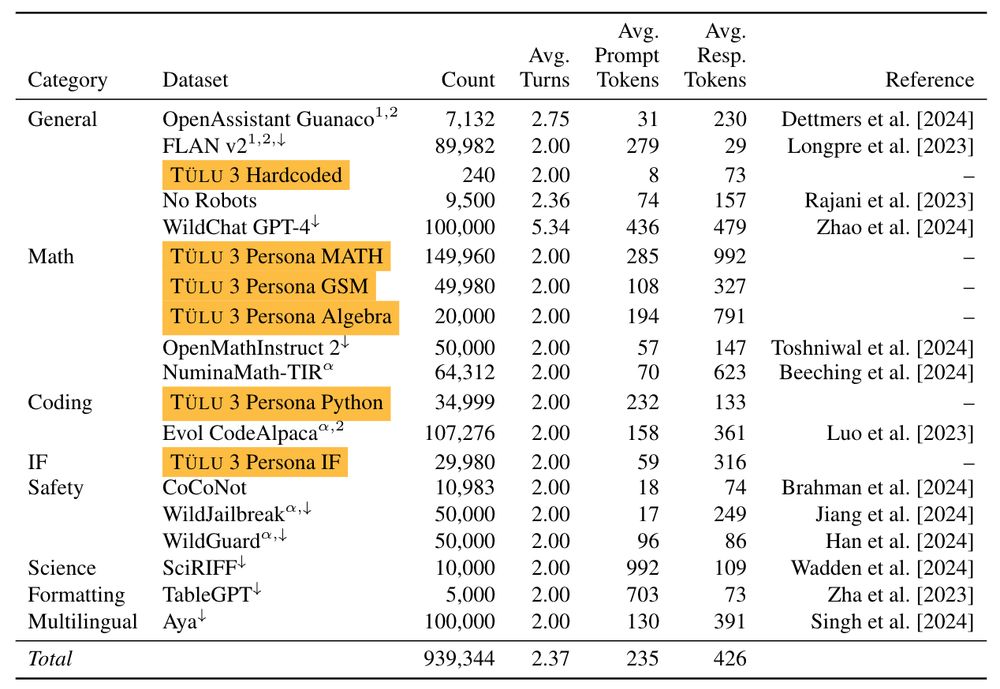
November 21, 2024 at 10:53 PM
What a gift to the community, this is going to contribute so much to the future of open source models. Nice work team. 🙌
This is an excellent rebuttal to a paper that I think gained way too much traction too easily. I really appreciate that the .txt team took the time and effort to put together such a well made case in favor of guided generation.

A new paper, "Let Me Speak Freely" has been spreading rumors that structured generation hurts LLM evaluation performance.
Well, we've taken a look and found serious issue in this paper, and shown, once again, that structured generation *improves* evaluation performance!
Well, we've taken a look and found serious issue in this paper, and shown, once again, that structured generation *improves* evaluation performance!
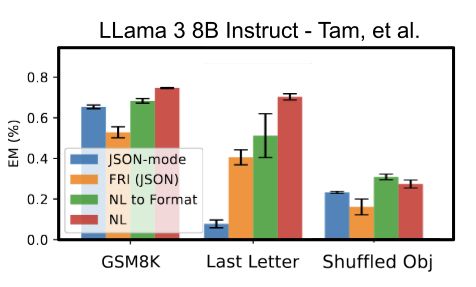
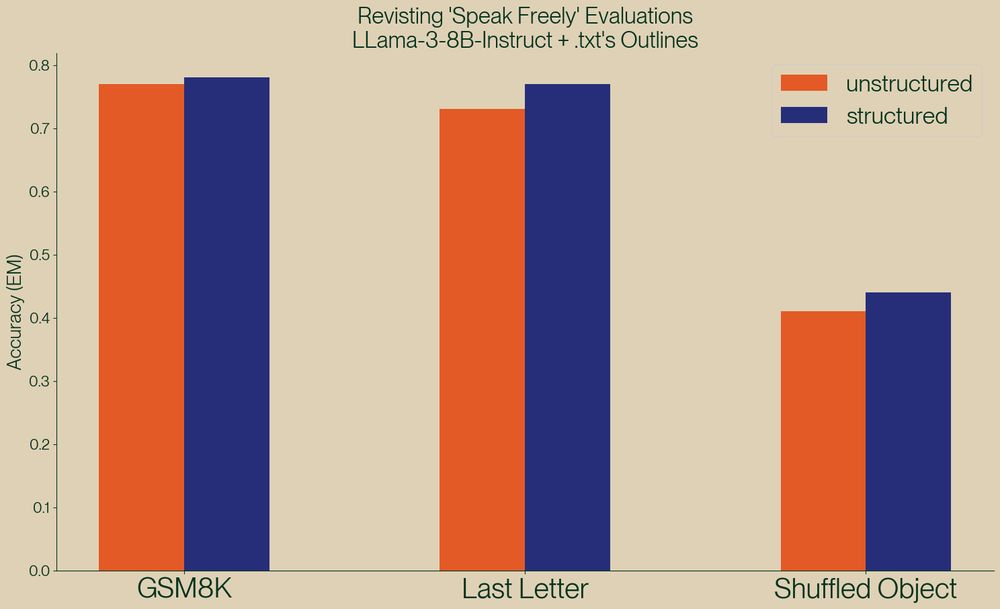
November 21, 2024 at 9:05 PM
This is an excellent rebuttal to a paper that I think gained way too much traction too easily. I really appreciate that the .txt team took the time and effort to put together such a well made case in favor of guided generation.
This is cool, very curious to see where things stand after enough data has worked its way through the ELO colon.
November 20, 2024 at 4:40 PM
This is cool, very curious to see where things stand after enough data has worked its way through the ELO colon.
the saddest kind of "ratio" is the fact that i have 60 posts and only 32 followers.
November 20, 2024 at 3:39 PM
the saddest kind of "ratio" is the fact that i have 60 posts and only 32 followers.
Really trying to figure out why "soft prompts" aren't used more often with LLMs. For those who aren't familiar, soft prompts are system prompts that have been converted to embedding space and then further optimized.
November 20, 2024 at 5:43 AM
Really trying to figure out why "soft prompts" aren't used more often with LLMs. For those who aren't familiar, soft prompts are system prompts that have been converted to embedding space and then further optimized.
I've been thinking more about the problem of ingesting tabular (ie visually structured data) from pdfs in llms. As far as I am aware, current paradigms use traditional computational methods to extract tables from pdfs (pymupdf, etc) before passing the structured data into LLMs as text.
November 19, 2024 at 8:39 AM
I've been thinking more about the problem of ingesting tabular (ie visually structured data) from pdfs in llms. As far as I am aware, current paradigms use traditional computational methods to extract tables from pdfs (pymupdf, etc) before passing the structured data into LLMs as text.
@jakehandy.com hi Jake, after lurking on ai/ml twitter for a long time I'm trying to make a serious effort to contribute to the conversation on here, focusing broadly on LLMs and narrowly on new paradigms for llm inference. Would appreciate an include on your starter pack. 🙌
November 19, 2024 at 8:11 AM
@jakehandy.com hi Jake, after lurking on ai/ml twitter for a long time I'm trying to make a serious effort to contribute to the conversation on here, focusing broadly on LLMs and narrowly on new paradigms for llm inference. Would appreciate an include on your starter pack. 🙌
Has anyone else found a pretty big discrepancy between using popular pdf extraction frameworks and submitting pdf data directly to llms?
November 17, 2024 at 10:21 PM
Has anyone else found a pretty big discrepancy between using popular pdf extraction frameworks and submitting pdf data directly to llms?
Really surprised how casually folks throw around the "year" agi will arrive. It should be pretty obvious that there will be a very long period (which started years ago) where models are superhuman in many ways but very deficienct in others.
November 16, 2024 at 10:59 PM
Really surprised how casually folks throw around the "year" agi will arrive. It should be pretty obvious that there will be a very long period (which started years ago) where models are superhuman in many ways but very deficienct in others.
LLM observation of the day: I think that guided/constrained generation gets a bad rap. There was one paper making the rounds about how guided generation harms reasoning ability that everyone took as gospel.
November 13, 2024 at 11:06 PM
LLM observation of the day: I think that guided/constrained generation gets a bad rap. There was one paper making the rounds about how guided generation harms reasoning ability that everyone took as gospel.
I have always used Twitter mostly passively, reading the content of others and occasionally chiming in with comments. Now that I have moved to bsky, I don't find as much ML content available, so I'm going to try to "be the ml content I wish to see I'm the world".
November 13, 2024 at 10:49 PM
I have always used Twitter mostly passively, reading the content of others and occasionally chiming in with comments. Now that I have moved to bsky, I don't find as much ML content available, so I'm going to try to "be the ml content I wish to see I'm the world".