


Mathieu Blondel
@mblondel.bsky.social
Research scientist, Google DeepMind
Reposted by Mathieu Blondel

📣 Please share: We invite submissions to the 29th International Conference on Artificial Intelligence and Statistics (#AISTATS 2026) and welcome paper submissions at the intersection of AI, machine learning, statistics, and related areas. [1/3]

August 12, 2025 at 11:46 AM
📣 Please share: We invite submissions to the 29th International Conference on Artificial Intelligence and Statistics (#AISTATS 2026) and welcome paper submissions at the intersection of AI, machine learning, statistics, and related areas. [1/3]
Reposted by Mathieu Blondel

I'm not on TV yet, but I'm on YouTube 😊 talking about research, ML, how I prepare talks and the difference between Bayesian and frequentist statistics.
Many thanks to Charles Riou who already posted many videos of interviews of ML & stats researchers on his YouTube channel "ML New Papers"!! 🙏
Many thanks to Charles Riou who already posted many videos of interviews of ML & stats researchers on his YouTube channel "ML New Papers"!! 🙏


April 28, 2025 at 11:08 AM
I'm not on TV yet, but I'm on YouTube 😊 talking about research, ML, how I prepare talks and the difference between Bayesian and frequentist statistics.
Many thanks to Charles Riou who already posted many videos of interviews of ML & stats researchers on his YouTube channel "ML New Papers"!! 🙏
Many thanks to Charles Riou who already posted many videos of interviews of ML & stats researchers on his YouTube channel "ML New Papers"!! 🙏
Reposted by Mathieu Blondel

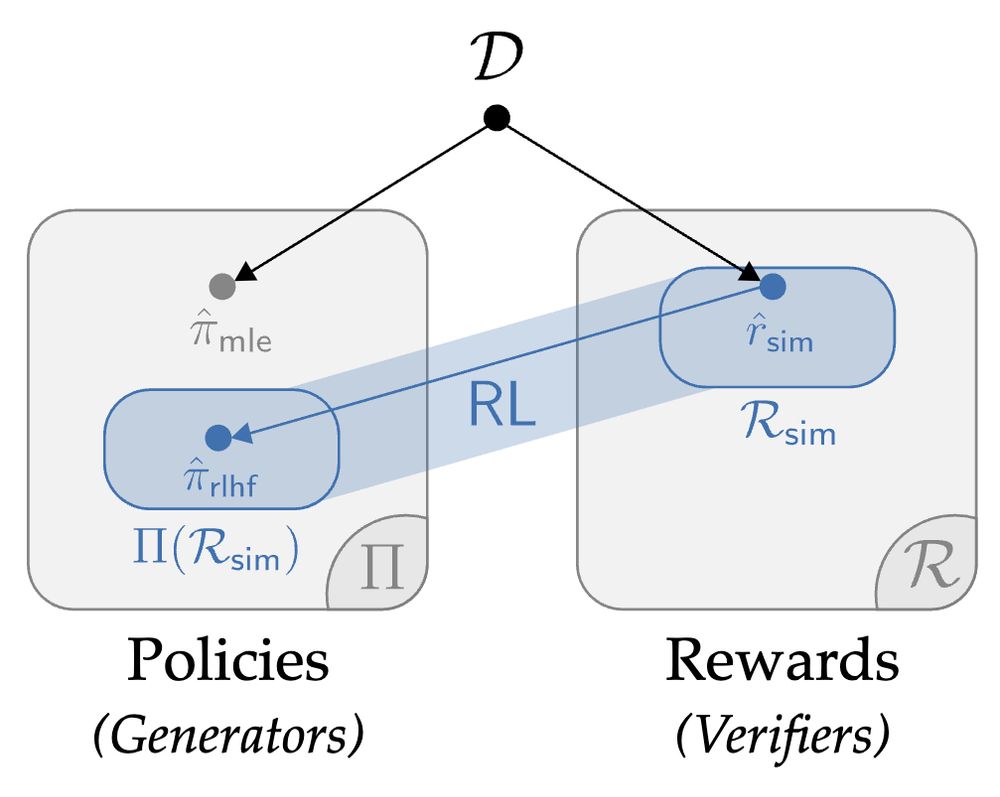
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
March 4, 2025 at 8:59 PM
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
Schrödinger's snack

February 18, 2025 at 8:43 AM
Schrödinger's snack
Reposted by Mathieu Blondel

🧗♂️Why GD converges beyond [step size]<2/[smoothness]? We investigate loss functions and identify their *separation margin* is an important factor. Surprisingly Renyi 2-entropy yields super fast rate T=Ω(ε^{-1/3})!
arxiv.org/abs/2502.04889
arxiv.org/abs/2502.04889




February 10, 2025 at 3:04 AM
🧗♂️Why GD converges beyond [step size]<2/[smoothness]? We investigate loss functions and identify their *separation margin* is an important factor. Surprisingly Renyi 2-entropy yields super fast rate T=Ω(ε^{-1/3})!
arxiv.org/abs/2502.04889
arxiv.org/abs/2502.04889
Reposted by Mathieu Blondel

Modern post-training is essentially distillation then RL. While reward hacking is well-known and feared, could there be such a thing as teacher hacking? Our latest paper confirms it. Fortunately, we also show how to mitigate it! The secret: diversity and onlineness! arxiv.org/abs/2502.02671
February 8, 2025 at 6:06 PM
Modern post-training is essentially distillation then RL. While reward hacking is well-known and feared, could there be such a thing as teacher hacking? Our latest paper confirms it. Fortunately, we also show how to mitigate it! The secret: diversity and onlineness! arxiv.org/abs/2502.02671
The EBM paper below parameterizes dual variables as neural nets. This idea (which has been used in other contexts such as OT or GANs) is very powerful and may be *the* way duality can be useful for neural nets (or rather, neural nets can be useful for duality!).
Really proud of these two companion papers by our team at GDM:
1) Joint Learning of Energy-based Models and their Partition Function
arxiv.org/abs/2501.18528
2) Loss Functions and Operators Generated by f-Divergences
arxiv.org/abs/2501.18537
A thread.
1) Joint Learning of Energy-based Models and their Partition Function
arxiv.org/abs/2501.18528
2) Loss Functions and Operators Generated by f-Divergences
arxiv.org/abs/2501.18537
A thread.
January 31, 2025 at 1:53 PM
The EBM paper below parameterizes dual variables as neural nets. This idea (which has been used in other contexts such as OT or GANs) is very powerful and may be *the* way duality can be useful for neural nets (or rather, neural nets can be useful for duality!).
Really proud of these two companion papers by our team at GDM:
1) Joint Learning of Energy-based Models and their Partition Function
arxiv.org/abs/2501.18528
2) Loss Functions and Operators Generated by f-Divergences
arxiv.org/abs/2501.18537
A thread.
1) Joint Learning of Energy-based Models and their Partition Function
arxiv.org/abs/2501.18528
2) Loss Functions and Operators Generated by f-Divergences
arxiv.org/abs/2501.18537
A thread.
January 31, 2025 at 12:06 PM
Really proud of these two companion papers by our team at GDM:
1) Joint Learning of Energy-based Models and their Partition Function
arxiv.org/abs/2501.18528
2) Loss Functions and Operators Generated by f-Divergences
arxiv.org/abs/2501.18537
A thread.
1) Joint Learning of Energy-based Models and their Partition Function
arxiv.org/abs/2501.18528
2) Loss Functions and Operators Generated by f-Divergences
arxiv.org/abs/2501.18537
A thread.
Reposted by Mathieu Blondel

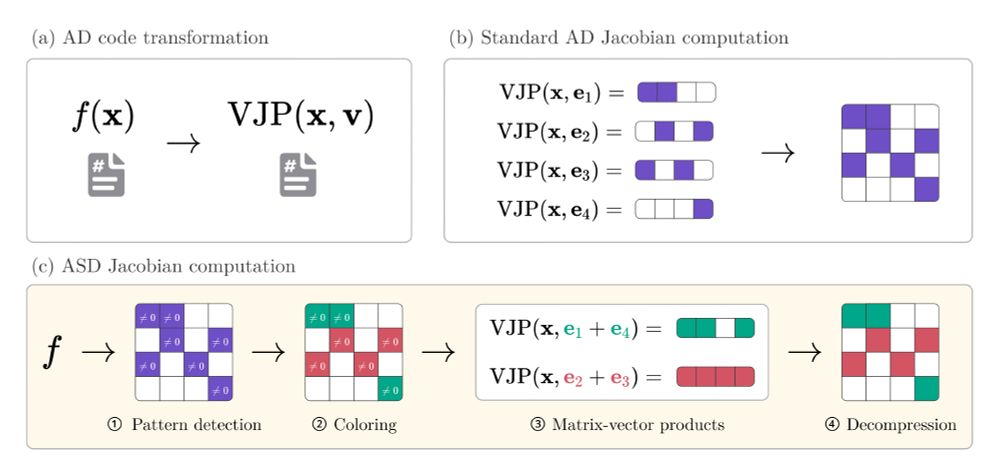
Sparser, better, faster, stronger

You think Jacobian and Hessian matrices are prohibitively expensive to compute on your problem? Our latest preprint with @gdalle.bsky.social might change your mind!
arxiv.org/abs/2501.17737
🧵1/8
arxiv.org/abs/2501.17737
🧵1/8
January 30, 2025 at 3:57 PM
Sparser, better, faster, stronger
Former French minister of Education and "philosopher" Luc Ferry, who said a few years ago that maths was useless, wrote a book on artificial intelligence 😂
January 27, 2025 at 11:57 AM
Former French minister of Education and "philosopher" Luc Ferry, who said a few years ago that maths was useless, wrote a book on artificial intelligence 😂
Reposted by Mathieu Blondel

We are organising the First International Conference on Probabilistic Numerics (ProbNum 2025) at EURECOM in southern France in Sep 2025. Topics: AI, ML, Stat, Sim, and Numerics. Reposts very much appreciated!
probnum25.github.io
probnum25.github.io

November 17, 2024 at 7:06 AM
We are organising the First International Conference on Probabilistic Numerics (ProbNum 2025) at EURECOM in southern France in Sep 2025. Topics: AI, ML, Stat, Sim, and Numerics. Reposts very much appreciated!
probnum25.github.io
probnum25.github.io
Reposted by Mathieu Blondel

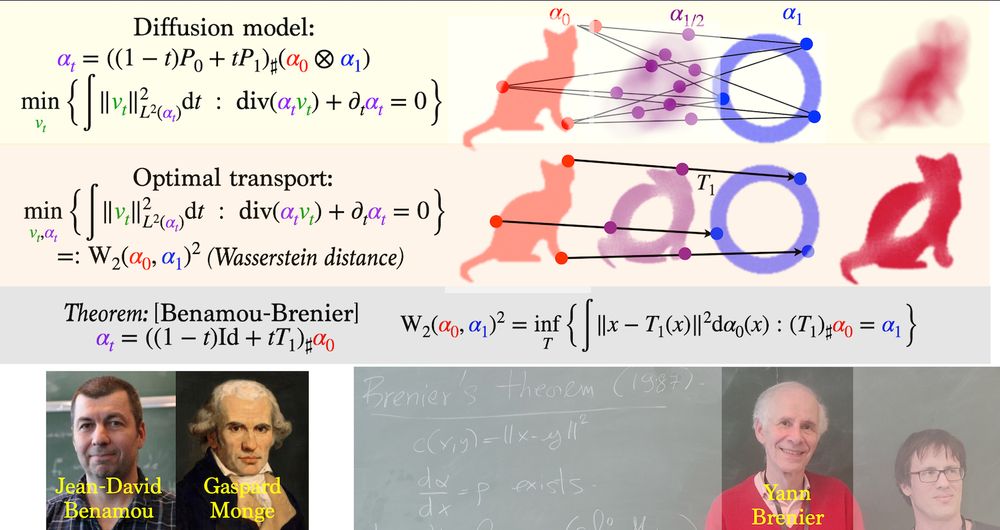
Slides for a general introduction to the use of Optimal Transport methods in learning, with an emphasis on diffusion models, flow matching, training 2 layers neural networks and deep transformers. speakerdeck.com/gpeyre/optim...
January 15, 2025 at 7:08 PM
Slides for a general introduction to the use of Optimal Transport methods in learning, with an emphasis on diffusion models, flow matching, training 2 layers neural networks and deep transformers. speakerdeck.com/gpeyre/optim...
Reposted by Mathieu Blondel

MLSS coming to Senegal !
📍 AIMS Mbour, Senegal
📅 June 23 - July 4, 2025
An international summer school to explore, collaborate, and deepen your understanding of machine learning in a unique and welcoming environment.
Details: mlss-senegal.github.io
📍 AIMS Mbour, Senegal
📅 June 23 - July 4, 2025
An international summer school to explore, collaborate, and deepen your understanding of machine learning in a unique and welcoming environment.
Details: mlss-senegal.github.io
MLSS Senegal 2025
mlss-senegal.github.io
December 12, 2024 at 8:45 AM
MLSS coming to Senegal !
📍 AIMS Mbour, Senegal
📅 June 23 - July 4, 2025
An international summer school to explore, collaborate, and deepen your understanding of machine learning in a unique and welcoming environment.
Details: mlss-senegal.github.io
📍 AIMS Mbour, Senegal
📅 June 23 - July 4, 2025
An international summer school to explore, collaborate, and deepen your understanding of machine learning in a unique and welcoming environment.
Details: mlss-senegal.github.io
Reposted by Mathieu Blondel

Thrilled to be co-organizing NeurIPS in Paris at @sorbonne-universite.fr next week!
📑 100 papers from NeurIPS 2024. Nearly twice as many as in 2023!
🧑🎓 over 300 registered participants
✅ a local and sustainable alternative to flying to Vancouver.
More info: neuripsinparis.github.io/neurips2024p...
📑 100 papers from NeurIPS 2024. Nearly twice as many as in 2023!
🧑🎓 over 300 registered participants
✅ a local and sustainable alternative to flying to Vancouver.
More info: neuripsinparis.github.io/neurips2024p...
4th and 5th of December Sorbonne Center for Artificial Intelligence (SCAI)
neuripsinparis.github.io
November 27, 2024 at 4:09 PM
Thrilled to be co-organizing NeurIPS in Paris at @sorbonne-universite.fr next week!
📑 100 papers from NeurIPS 2024. Nearly twice as many as in 2023!
🧑🎓 over 300 registered participants
✅ a local and sustainable alternative to flying to Vancouver.
More info: neuripsinparis.github.io/neurips2024p...
📑 100 papers from NeurIPS 2024. Nearly twice as many as in 2023!
🧑🎓 over 300 registered participants
✅ a local and sustainable alternative to flying to Vancouver.
More info: neuripsinparis.github.io/neurips2024p...
Why would blue sky be more successful than mastodon at replacing twitter for the scientific community? (honest question)
November 23, 2024 at 5:52 PM
Why would blue sky be more successful than mastodon at replacing twitter for the scientific community? (honest question)