



Hermann Blum
@hermannblum.bsky.social
ML & CV for robot perception
assistant professor @ Uni Bonn & Lamarr Institute
interested in self-learning & autonomous robots, likes all the messy hardware problems of real-world experiments
https://rpl.uni-bonn.de/
https://hermannblum.net/
assistant professor @ Uni Bonn & Lamarr Institute
interested in self-learning & autonomous robots, likes all the messy hardware problems of real-world experiments
https://rpl.uni-bonn.de/
https://hermannblum.net/
CroCoDL Workshop at #ICCV, next talk coming up in Room 301B:
16.30 - 17.00: @sattlertorsten.bsky.social on Vision Localization Across Modalities
full schedule: localizoo.com/workshop
16.30 - 17.00: @sattlertorsten.bsky.social on Vision Localization Across Modalities
full schedule: localizoo.com/workshop

October 21, 2025 at 2:15 AM
CroCoDL Workshop at #ICCV, next talk coming up in Room 301B:
16.30 - 17.00: @sattlertorsten.bsky.social on Vision Localization Across Modalities
full schedule: localizoo.com/workshop
16.30 - 17.00: @sattlertorsten.bsky.social on Vision Localization Across Modalities
full schedule: localizoo.com/workshop
In 30 mins! CroCoDL Poster Session (posters #248-#257), during the official coffee break 3pm - 4pm.
Contributed works cover Visual Localization, Visual Place Recognition, Room Layout Estimation, Novel View Synthesis, 3D Reconstruction
Contributed works cover Visual Localization, Visual Place Recognition, Room Layout Estimation, Novel View Synthesis, 3D Reconstruction

October 21, 2025 at 12:30 AM
In 30 mins! CroCoDL Poster Session (posters #248-#257), during the official coffee break 3pm - 4pm.
Contributed works cover Visual Localization, Visual Place Recognition, Room Layout Estimation, Novel View Synthesis, 3D Reconstruction
Contributed works cover Visual Localization, Visual Place Recognition, Room Layout Estimation, Novel View Synthesis, 3D Reconstruction
CroCoDL Workshop at #ICCV, next talk coming up in Room 301B:
14.15 - 14.45: @ayoungk.bsky.social on Bridging heterogeneous sensors for robust and generalizable localization
full schedule: localizoo.com/workshop/
14.15 - 14.45: @ayoungk.bsky.social on Bridging heterogeneous sensors for robust and generalizable localization
full schedule: localizoo.com/workshop/

October 21, 2025 at 12:00 AM
CroCoDL Workshop at #ICCV, next talk coming up in Room 301B:
14.15 - 14.45: @ayoungk.bsky.social on Bridging heterogeneous sensors for robust and generalizable localization
full schedule: localizoo.com/workshop/
14.15 - 14.45: @ayoungk.bsky.social on Bridging heterogeneous sensors for robust and generalizable localization
full schedule: localizoo.com/workshop/
CroCoDL Workshop at #ICCV, next talk coming up in Room 301B:
13.15 - 13.45: @gabrielacsurka.bsky.social on Privacy Preserving Visual Localization
full schedule: buff.ly/kM1Ompf
13.15 - 13.45: @gabrielacsurka.bsky.social on Privacy Preserving Visual Localization
full schedule: buff.ly/kM1Ompf

October 20, 2025 at 11:01 PM
CroCoDL Workshop at #ICCV, next talk coming up in Room 301B:
13.15 - 13.45: @gabrielacsurka.bsky.social on Privacy Preserving Visual Localization
full schedule: buff.ly/kM1Ompf
13.15 - 13.45: @gabrielacsurka.bsky.social on Privacy Preserving Visual Localization
full schedule: buff.ly/kM1Ompf
Attending #ICCV? Join the CroCoDL workshop this afternoon!
localizoo.com/workshop
Speakers: @gabrielacsurka.bsky.social, @ayoungk.bsky.social, David Caruso, @sattlertorsten.bsky.social
w/ @zbauer.bsky.social @mihaidusmanu.bsky.social @linfeipan.bsky.social @marcpollefeys.bsky.social
localizoo.com/workshop
Speakers: @gabrielacsurka.bsky.social, @ayoungk.bsky.social, David Caruso, @sattlertorsten.bsky.social
w/ @zbauer.bsky.social @mihaidusmanu.bsky.social @linfeipan.bsky.social @marcpollefeys.bsky.social
October 20, 2025 at 9:01 PM
Attending #ICCV? Join the CroCoDL workshop this afternoon!
localizoo.com/workshop
Speakers: @gabrielacsurka.bsky.social, @ayoungk.bsky.social, David Caruso, @sattlertorsten.bsky.social
w/ @zbauer.bsky.social @mihaidusmanu.bsky.social @linfeipan.bsky.social @marcpollefeys.bsky.social
localizoo.com/workshop
Speakers: @gabrielacsurka.bsky.social, @ayoungk.bsky.social, David Caruso, @sattlertorsten.bsky.social
w/ @zbauer.bsky.social @mihaidusmanu.bsky.social @linfeipan.bsky.social @marcpollefeys.bsky.social
Today a delivery arrived that marks an exciting milestone for my lab: our first research grant!

September 5, 2025 at 7:59 PM
Today a delivery arrived that marks an exciting milestone for my lab: our first research grant!
We just released code, models, and data for FrontierNet!
Key idea 💡Instead of detecting froniers in a map, we directly predict them from images. Hence, FrontierNet can implicitly learn visual semantic priors to estimate information gain. That speeds up exploration compared to geometric heuristics.
Key idea 💡Instead of detecting froniers in a map, we directly predict them from images. Hence, FrontierNet can implicitly learn visual semantic priors to estimate information gain. That speeds up exploration compared to geometric heuristics.
July 17, 2025 at 8:34 AM
We just released code, models, and data for FrontierNet!
Key idea 💡Instead of detecting froniers in a map, we directly predict them from images. Hence, FrontierNet can implicitly learn visual semantic priors to estimate information gain. That speeds up exploration compared to geometric heuristics.
Key idea 💡Instead of detecting froniers in a map, we directly predict them from images. Hence, FrontierNet can implicitly learn visual semantic priors to estimate information gain. That speeds up exploration compared to geometric heuristics.
Reposted by Hermann Blum

Looking for a venue for your paper related to mapping / localization / retrieval / egocentric & embodied AI / domain shift / others ? Our ICCV 2025 workshop CroCoDL is still open for 8-page original submissions until the 30th of June via OpenReview: openreview.net/group?id=the....
June 27, 2025 at 7:15 AM
Looking for a venue for your paper related to mapping / localization / retrieval / egocentric & embodied AI / domain shift / others ? Our ICCV 2025 workshop CroCoDL is still open for 8-page original submissions until the 30th of June via OpenReview: openreview.net/group?id=the....
This is the first time in a while I am creating a new talk. This will be fun!
I'll be up later today at the Visual SLAM workshop at @roboticsscisys.bsky.social
buff.ly/ADHxPsX
I'll be up later today at the Visual SLAM workshop at @roboticsscisys.bsky.social
buff.ly/ADHxPsX

June 21, 2025 at 8:34 AM
This is the first time in a while I am creating a new talk. This will be fun!
I'll be up later today at the Visual SLAM workshop at @roboticsscisys.bsky.social
buff.ly/ADHxPsX
I'll be up later today at the Visual SLAM workshop at @roboticsscisys.bsky.social
buff.ly/ADHxPsX
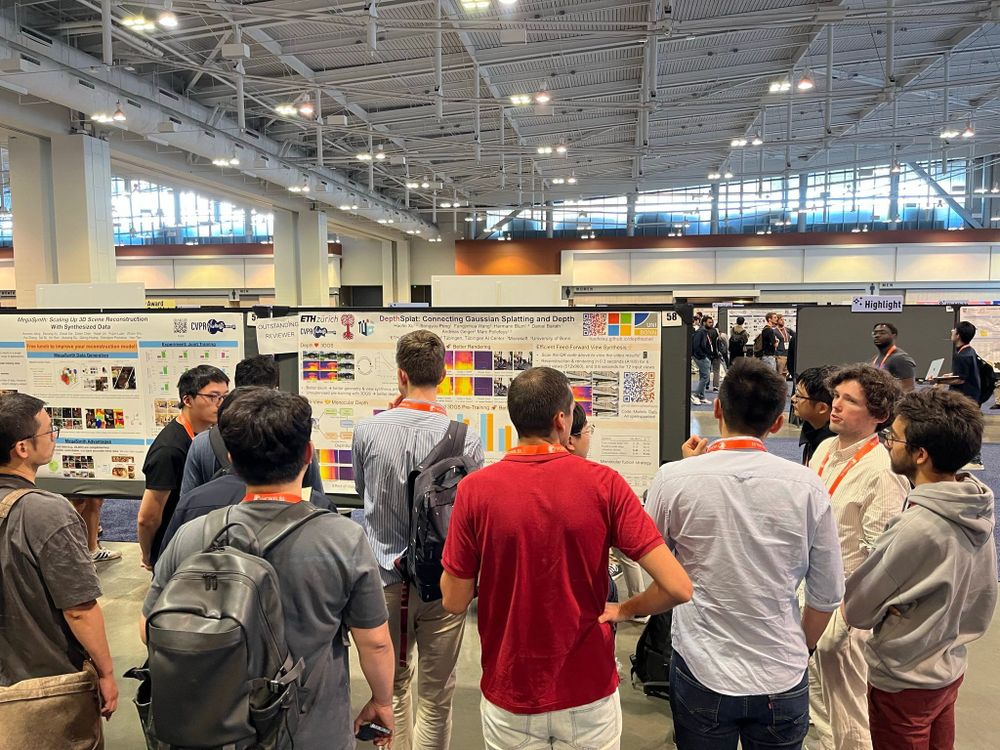
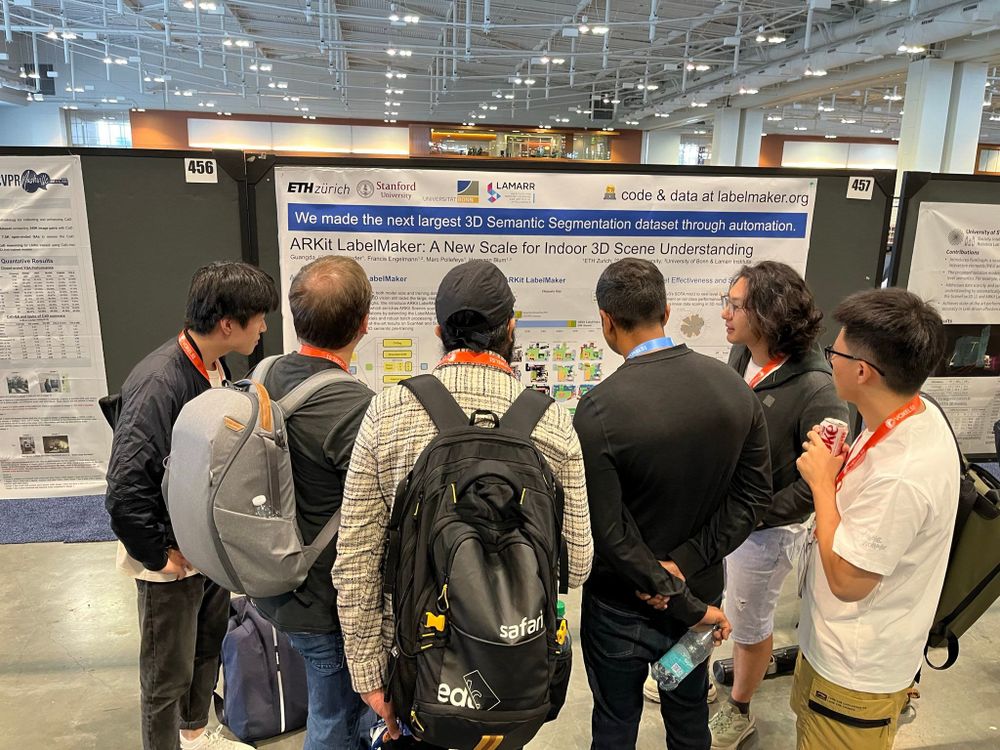
Finally arriving home today after attending @cvprconference.bsky.social . This was the first #CVPR that I could attend in person! I expected it to be super crowded but was surprised - lots of time and space for chats at the poster session and the 15min talks could really go into detail.


June 19, 2025 at 2:58 PM
Finally arriving home today after attending @cvprconference.bsky.social . This was the first #CVPR that I could attend in person! I expected it to be super crowded but was surprised - lots of time and space for chats at the poster session and the 15min talks could really go into detail.
Reposted by Hermann Blum

Do you want to learn more about our novel dataset for Cross-device localization? Come by poster 121 and meet CroCoDL 🐊
cc @marcpollefeys.bsky.social @hermannblum.bsky.social @mihaidusmanu.bsky.social @cvprconference.bsky.social @ethz.ch
cc @marcpollefeys.bsky.social @hermannblum.bsky.social @mihaidusmanu.bsky.social @cvprconference.bsky.social @ethz.ch

June 15, 2025 at 5:54 PM
Do you want to learn more about our novel dataset for Cross-device localization? Come by poster 121 and meet CroCoDL 🐊
cc @marcpollefeys.bsky.social @hermannblum.bsky.social @mihaidusmanu.bsky.social @cvprconference.bsky.social @ethz.ch
cc @marcpollefeys.bsky.social @hermannblum.bsky.social @mihaidusmanu.bsky.social @cvprconference.bsky.social @ethz.ch
We just extended our submission deadline for 8-page paper submissions until June 30.
Accepted submissions go into ICCV WS proceedings 📄
Accepted submissions go into ICCV WS proceedings 📄
🌺 Excited to announce the 1st CroCoDL Workshop on Large-Scale Cross-Device Localization at #ICCV2025!
Tackling real-world localization across smartphones, AR/VR, and robots with invited talks, paper track & competition on a novel dataset.
🔗 localizoo.com/workshop
🧵 1/2
Tackling real-world localization across smartphones, AR/VR, and robots with invited talks, paper track & competition on a novel dataset.
🔗 localizoo.com/workshop
🧵 1/2

June 14, 2025 at 9:31 PM
We just extended our submission deadline for 8-page paper submissions until June 30.
Accepted submissions go into ICCV WS proceedings 📄
Accepted submissions go into ICCV WS proceedings 📄
all set for our poster lineup at the cv4mr.github.io #cvpr workshop

June 11, 2025 at 3:32 PM
all set for our poster lineup at the cv4mr.github.io #cvpr workshop
I‘ll be at CVPR this week and I am actively looking for PhD students (job announcement will go out the week after). Just send me a message if you are interested to meet up.
June 9, 2025 at 5:19 PM
I‘ll be at CVPR this week and I am actively looking for PhD students (job announcement will go out the week after). Just send me a message if you are interested to meet up.
Reposted by Hermann Blum

Excited to present our #CVPR2025 paper DepthSplat next week!
DepthSplat is a feed-forward model that achieves high-quality Gaussian reconstruction and view synthesis in just 0.6 seconds.
Looking forward to great conversations at the conference!
DepthSplat is a feed-forward model that achieves high-quality Gaussian reconstruction and view synthesis in just 0.6 seconds.
Looking forward to great conversations at the conference!
🏠 Introducing DepthSplat: a framework that connects Gaussian splatting with single- and multi-view depth estimation. This enables robust depth modeling and high-quality view synthesis with state-of-the-art results on ScanNet, RealEstate10K, and DL3DV.
🔗 haofeixu.github.io/depthsplat/
🔗 haofeixu.github.io/depthsplat/
June 5, 2025 at 12:09 PM
Excited to present our #CVPR2025 paper DepthSplat next week!
DepthSplat is a feed-forward model that achieves high-quality Gaussian reconstruction and view synthesis in just 0.6 seconds.
Looking forward to great conversations at the conference!
DepthSplat is a feed-forward model that achieves high-quality Gaussian reconstruction and view synthesis in just 0.6 seconds.
Looking forward to great conversations at the conference!
If you‘re watching #eurovision tonight, look out for the robots from ETH!
Really cool to see something I could work with during my PhD featured as a swiss highlight 🤖
Really cool to see something I could work with during my PhD featured as a swiss highlight 🤖

May 17, 2025 at 7:37 PM
If you‘re watching #eurovision tonight, look out for the robots from ETH!
Really cool to see something I could work with during my PhD featured as a swiss highlight 🤖
Really cool to see something I could work with during my PhD featured as a swiss highlight 🤖
We are organizing the 1st Workshop on Cross-Device Visual Localization at #ICCV #ICCV2025
Localizing multiple phones, headsets, and robots to a common reference frame is so far a real problem in mixed-reality applications. Our new challenge will track progress on this issue.
⏰ paper deadline: June 6
Localizing multiple phones, headsets, and robots to a common reference frame is so far a real problem in mixed-reality applications. Our new challenge will track progress on this issue.
⏰ paper deadline: June 6
🌺 Excited to announce the 1st CroCoDL Workshop on Large-Scale Cross-Device Localization at #ICCV2025!
Tackling real-world localization across smartphones, AR/VR, and robots with invited talks, paper track & competition on a novel dataset.
🔗 localizoo.com/workshop
🧵 1/2
Tackling real-world localization across smartphones, AR/VR, and robots with invited talks, paper track & competition on a novel dataset.
🔗 localizoo.com/workshop
🧵 1/2
May 13, 2025 at 3:13 PM
Reposted by Hermann Blum

🏠 Introducing DepthSplat: a framework that connects Gaussian splatting with single- and multi-view depth estimation. This enables robust depth modeling and high-quality view synthesis with state-of-the-art results on ScanNet, RealEstate10K, and DL3DV.
🔗 haofeixu.github.io/depthsplat/
🔗 haofeixu.github.io/depthsplat/
April 24, 2025 at 8:58 AM
🏠 Introducing DepthSplat: a framework that connects Gaussian splatting with single- and multi-view depth estimation. This enables robust depth modeling and high-quality view synthesis with state-of-the-art results on ScanNet, RealEstate10K, and DL3DV.
🔗 haofeixu.github.io/depthsplat/
🔗 haofeixu.github.io/depthsplat/
Exciting news for LabelMaker!
1️⃣ ARKitLabelMaker, the largest annotated 3D dataset, was accepted to CVPR 2025! This was an amazing effort of Guangda Ji 👏
🔗 labelmaker.org
📄 arxiv.org/abs/2410.13924
2️⃣ Mahta Moshkelgosha extended the pipeline to generate 3D scene graphs:
👩💻 github.com/cvg/LabelMak...
1️⃣ ARKitLabelMaker, the largest annotated 3D dataset, was accepted to CVPR 2025! This was an amazing effort of Guangda Ji 👏
🔗 labelmaker.org
📄 arxiv.org/abs/2410.13924
2️⃣ Mahta Moshkelgosha extended the pipeline to generate 3D scene graphs:
👩💻 github.com/cvg/LabelMak...
LabelMaker 🎨
LabelMaker
labelmaker.org
April 2, 2025 at 5:35 PM
Exciting news for LabelMaker!
1️⃣ ARKitLabelMaker, the largest annotated 3D dataset, was accepted to CVPR 2025! This was an amazing effort of Guangda Ji 👏
🔗 labelmaker.org
📄 arxiv.org/abs/2410.13924
2️⃣ Mahta Moshkelgosha extended the pipeline to generate 3D scene graphs:
👩💻 github.com/cvg/LabelMak...
1️⃣ ARKitLabelMaker, the largest annotated 3D dataset, was accepted to CVPR 2025! This was an amazing effort of Guangda Ji 👏
🔗 labelmaker.org
📄 arxiv.org/abs/2410.13924
2️⃣ Mahta Moshkelgosha extended the pipeline to generate 3D scene graphs:
👩💻 github.com/cvg/LabelMak...
Reposted by Hermann Blum

*Please repost* @sjgreenwood.bsky.social and I just launched a new personalized feed (*please pin*) that we hope will become a "must use" for #academicsky. The feed shows posts about papers filtered by *your* follower network. It's become my default Bluesky experience bsky.app/profile/pape...
March 10, 2025 at 6:14 PM
*Please repost* @sjgreenwood.bsky.social and I just launched a new personalized feed (*please pin*) that we hope will become a "must use" for #academicsky. The feed shows posts about papers filtered by *your* follower network. It's become my default Bluesky experience bsky.app/profile/pape...
Reposted by Hermann Blum

Open source code now available MASt3R-SLAM: the best dense visual SLAM system I've ever seen. Real-time and monocular, and easy to run with a live camera or on videos without needing to know the camera calibration. Brilliant work from Eric and Riku.

MASt3R-SLAM code release!
github.com/rmurai0610/M...
Try it out on videos or with a live camera
Work with
@ericdexheimer.bsky.social*,
@ajdavison.bsky.social (*Equal Contribution)
github.com/rmurai0610/M...
Try it out on videos or with a live camera
Work with
@ericdexheimer.bsky.social*,
@ajdavison.bsky.social (*Equal Contribution)
Introducing MASt3R-SLAM, the first real-time monocular dense SLAM with MASt3R as a foundation.
Easy to use like DUSt3R/MASt3R, from an uncalibrated RGB video it recovers accurate, globally consistent poses & a dense map.
With @ericdexheimer.bsky.social* @ajdavison.bsky.social (*Equal Contribution)
Easy to use like DUSt3R/MASt3R, from an uncalibrated RGB video it recovers accurate, globally consistent poses & a dense map.
With @ericdexheimer.bsky.social* @ajdavison.bsky.social (*Equal Contribution)
February 25, 2025 at 5:34 PM
Open source code now available MASt3R-SLAM: the best dense visual SLAM system I've ever seen. Real-time and monocular, and easy to run with a live camera or on videos without needing to know the camera calibration. Brilliant work from Eric and Riku.
We have an excellent opportunity for a tenured, flagship AI professorship at @unibonn.bsky.social and lamarr-institute.org
Application Deadline is End of March.
www.uni-bonn.de/en/universit...
Application Deadline is End of March.
www.uni-bonn.de/en/universit...
Full Professorship (W3) in Artificial Intelligence and Machine Learning
W3 Professorship
www.uni-bonn.de
February 24, 2025 at 7:19 PM
We have an excellent opportunity for a tenured, flagship AI professorship at @unibonn.bsky.social and lamarr-institute.org
Application Deadline is End of March.
www.uni-bonn.de/en/universit...
Application Deadline is End of March.
www.uni-bonn.de/en/universit...
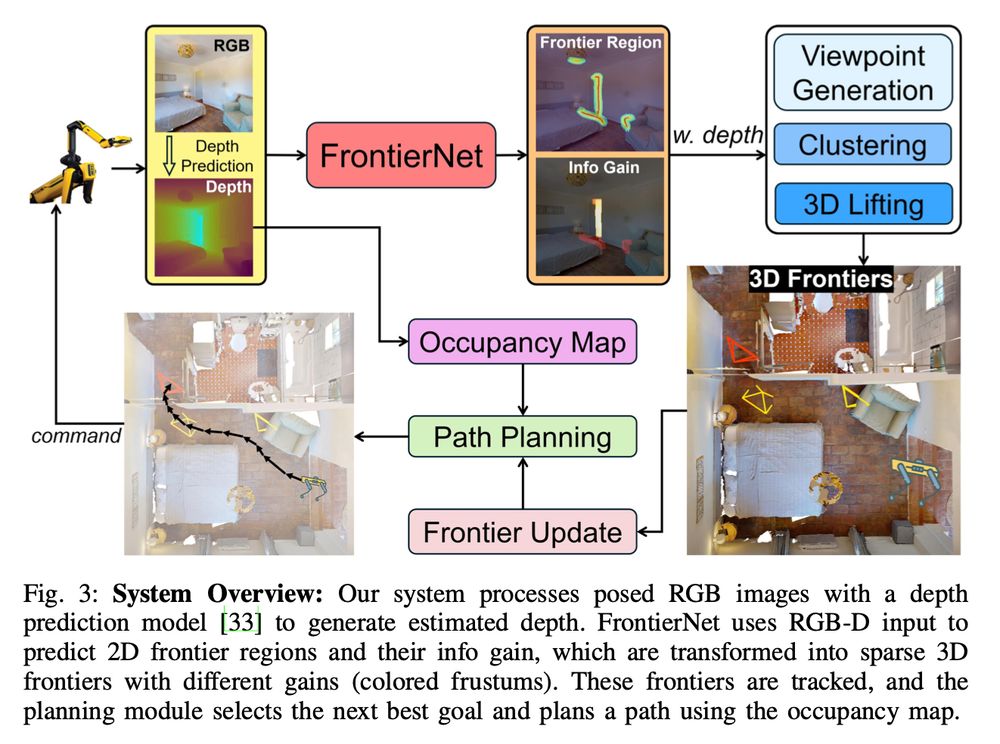
Very proud of Boyang for this work, great to see first shoutouts!
The gist is that exploration has always been treated as a geometric problem, but we show visual cues are really helpful to detect frontiers and predict their info gain.
W/ FrontierNet, you can get RGB-only exploration/object search/+
The gist is that exploration has always been treated as a geometric problem, but we show visual cues are really helpful to detect frontiers and predict their info gain.
W/ FrontierNet, you can get RGB-only exploration/object search/+

FrontierNet: Learning Visual Cues to Explore
Boyang Sun, Hanzhi Chen, Stefan Leutenegger, Cesar Cadena, @marcpollefeys.bsky.social , Hermann Blum
tl;dr: predict frontier (where we weren't yet) using RGBD and then make a map, and not otherwise.
arxiv.org/abs/2501.04597
Boyang Sun, Hanzhi Chen, Stefan Leutenegger, Cesar Cadena, @marcpollefeys.bsky.social , Hermann Blum
tl;dr: predict frontier (where we weren't yet) using RGBD and then make a map, and not otherwise.
arxiv.org/abs/2501.04597



February 5, 2025 at 3:35 PM
Very proud of Boyang for this work, great to see first shoutouts!
The gist is that exploration has always been treated as a geometric problem, but we show visual cues are really helpful to detect frontiers and predict their info gain.
W/ FrontierNet, you can get RGB-only exploration/object search/+
The gist is that exploration has always been treated as a geometric problem, but we show visual cues are really helpful to detect frontiers and predict their info gain.
W/ FrontierNet, you can get RGB-only exploration/object search/+
Turns out aria-glasses are a very useful tool to demonstrate actions to robots: Based on egocentric video we track dynamic changes in a scene graph and use the representation to replay or plan interactions for robots
🔗 behretj.github.io/LostAndFound/
📄 arxiv.org/abs/2411.19162
📺 youtu.be/xxMsaBSeMXo
🔗 behretj.github.io/LostAndFound/
📄 arxiv.org/abs/2411.19162
📺 youtu.be/xxMsaBSeMXo
December 3, 2024 at 12:01 PM
Turns out aria-glasses are a very useful tool to demonstrate actions to robots: Based on egocentric video we track dynamic changes in a scene graph and use the representation to replay or plan interactions for robots
🔗 behretj.github.io/LostAndFound/
📄 arxiv.org/abs/2411.19162
📺 youtu.be/xxMsaBSeMXo
🔗 behretj.github.io/LostAndFound/
📄 arxiv.org/abs/2411.19162
📺 youtu.be/xxMsaBSeMXo
Reposted by Hermann Blum

Applications are open for student researcher positions at Google DeepMind for 2025! Due date Dec 13
www.google.com/about/career...
www.google.com/about/career...
Student Researcher, 2025 — Google Careers
www.google.com
November 27, 2024 at 1:17 AM
Applications are open for student researcher positions at Google DeepMind for 2025! Due date Dec 13
www.google.com/about/career...
www.google.com/about/career...