



Giuseppe
@giusfra.bsky.social
ML Software Engineer @ AMD. Working on open source quantization.
Pinned
Giuseppe
@giusfra.bsky.social
· Nov 24

GitHub - Xilinx/brevitas: Brevitas: neural network quantization in PyTorch
Brevitas: neural network quantization in PyTorch. Contribute to Xilinx/brevitas development by creating an account on GitHub.
github.com
Hello!
I'm Giuseppe, currently working at AMD on open-source ML quantization.
If that's something you're interested in, check out: github.com/Xilinx/brevi...
We support all the fanciest SOTA quantization algorithm, with a focus on modularity and composability.
I'm Giuseppe, currently working at AMD on open-source ML quantization.
If that's something you're interested in, check out: github.com/Xilinx/brevi...
We support all the fanciest SOTA quantization algorithm, with a focus on modularity and composability.
Reposted by Giuseppe

Giuseppe Franco, Pablo Monteagudo-Lago, Ian Colbert, Nicholas Fraser, Michaela Blott: Improving Quantization with Post-Training Model Expansion https://arxiv.org/abs/2503.17513 https://arxiv.org/pdf/2503.17513 https://arxiv.org/html/2503.17513
March 25, 2025 at 6:00 AM
Giuseppe Franco, Pablo Monteagudo-Lago, Ian Colbert, Nicholas Fraser, Michaela Blott: Improving Quantization with Post-Training Model Expansion https://arxiv.org/abs/2503.17513 https://arxiv.org/pdf/2503.17513 https://arxiv.org/html/2503.17513
Some interesting news on the Brevitas front!
We recently published a small paper analyzing how post-training model expansion can add more flexibility during quantization time.
It is possible to improve the accuracy of your quantized model by slightly increasing your model size, without retraining.
We recently published a small paper analyzing how post-training model expansion can add more flexibility during quantization time.
It is possible to improve the accuracy of your quantized model by slightly increasing your model size, without retraining.
March 27, 2025 at 9:59 AM
Some interesting news on the Brevitas front!
We recently published a small paper analyzing how post-training model expansion can add more flexibility during quantization time.
It is possible to improve the accuracy of your quantized model by slightly increasing your model size, without retraining.
We recently published a small paper analyzing how post-training model expansion can add more flexibility during quantization time.
It is possible to improve the accuracy of your quantized model by slightly increasing your model size, without retraining.
Reposted by Giuseppe

Cecilia Sala, a prominent Italian journalist, was arrested in Iran and jailed in the country’s infamous Evin prison after spending days reporting in Tehran, Italian officials said. The reason for the arrest has not been made public.

Italian Journalist Is Detained While Reporting in Iran
Cecilia Sala, 29, was arrested on Dec. 19, but news of her detention only became public on Friday. The reason for the arrest of Ms. Sala, a well-known reporter, has not been made public.
www.nytimes.com
December 27, 2024 at 3:52 PM
Cecilia Sala, a prominent Italian journalist, was arrested in Iran and jailed in the country’s infamous Evin prison after spending days reporting in Tehran, Italian officials said. The reason for the arrest has not been made public.
Thanks everyone for this work and the insights about the most used transformers models!
It helps to put things in perspective and step away from the sometimes unjustified LLM hype.
It helps to put things in perspective and step away from the sometimes unjustified LLM hype.
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
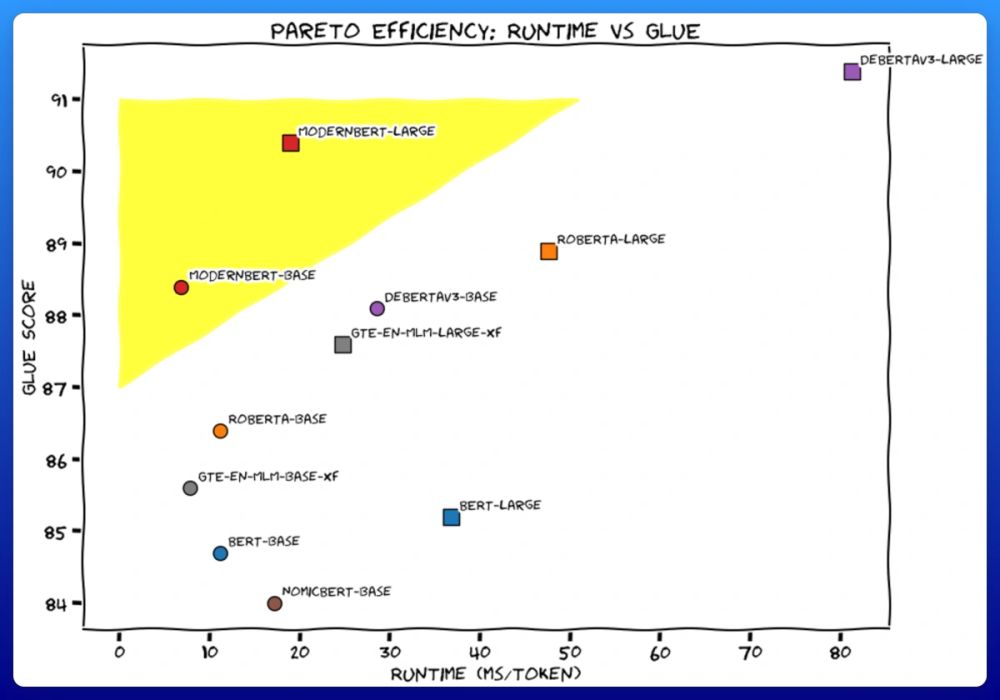
December 20, 2024 at 12:34 PM
Thanks everyone for this work and the insights about the most used transformers models!
It helps to put things in perspective and step away from the sometimes unjustified LLM hype.
It helps to put things in perspective and step away from the sometimes unjustified LLM hype.
If you're at #NeurIPS, Ian Colbert will give a talk about Brevitas and how #AMD is preparing for the next generation of data types!
If you're interested in accumulation aware quantization or you want to see some interesting results on 4bit LLM quantization with Integer/minifloat/MX, check it out!
If you're interested in accumulation aware quantization or you want to see some interesting results on 4bit LLM quantization with Integer/minifloat/MX, check it out!
December 9, 2024 at 6:52 PM
Reposted by Giuseppe

The Lichess database of games, puzzles, and engine evaluations is now on @hf.co - https://huggingface.co/Lichess. Billions of chess data points to download, query, and stream and we're excited to see what you'll build with it! ♟️ 🤗
December 6, 2024 at 9:46 AM
The Lichess database of games, puzzles, and engine evaluations is now on @hf.co - https://huggingface.co/Lichess. Billions of chess data points to download, query, and stream and we're excited to see what you'll build with it! ♟️ 🤗
Reposted by Giuseppe

Good, published, benchmarks of machine learning / data science is crucial.
But so hard.
Well-cited "SOTA" methods typically crash often. They tend to be very computational expensive. Both make a systematic study impossible.
Finally, reviewers always ask for more methods, and more "SOTA".
But so hard.
Well-cited "SOTA" methods typically crash often. They tend to be very computational expensive. Both make a systematic study impossible.
Finally, reviewers always ask for more methods, and more "SOTA".

December 1, 2024 at 4:54 PM
Good, published, benchmarks of machine learning / data science is crucial.
But so hard.
Well-cited "SOTA" methods typically crash often. They tend to be very computational expensive. Both make a systematic study impossible.
Finally, reviewers always ask for more methods, and more "SOTA".
But so hard.
Well-cited "SOTA" methods typically crash often. They tend to be very computational expensive. Both make a systematic study impossible.
Finally, reviewers always ask for more methods, and more "SOTA".
Reposted by Giuseppe

FYI, here's the entire code to create a dataset of every single bsky message in real time:
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
November 28, 2024 at 9:56 AM
FYI, here's the entire code to create a dataset of every single bsky message in real time:
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
While we prepare the next release of Brevitas, check out the 0.11.0 release here: github.com/Xilinx/brevi...
Lots of new things, including:
- QAT/PTQ for minifloat
- QAT/PTQ for MX Int and MX Float
- Compatibility with huggingface's accelerate
- New PTQ techniques (HQQ, Channel splitting)
Lots of new things, including:
- QAT/PTQ for minifloat
- QAT/PTQ for MX Int and MX Float
- Compatibility with huggingface's accelerate
- New PTQ techniques (HQQ, Channel splitting)

Release Release v0.11.0 · Xilinx/brevitas
Breaking Changes
Remove ONNX QOp export (#917)
QuantTensor cannot have empty metadata fields (e.g., scale, bitwidth, etc.) (#819)
Bias quantization now requires the specification of bit-width (#83...
github.com
November 27, 2024 at 11:12 PM
While we prepare the next release of Brevitas, check out the 0.11.0 release here: github.com/Xilinx/brevi...
Lots of new things, including:
- QAT/PTQ for minifloat
- QAT/PTQ for MX Int and MX Float
- Compatibility with huggingface's accelerate
- New PTQ techniques (HQQ, Channel splitting)
Lots of new things, including:
- QAT/PTQ for minifloat
- QAT/PTQ for MX Int and MX Float
- Compatibility with huggingface's accelerate
- New PTQ techniques (HQQ, Channel splitting)
Reposted by Giuseppe

“a protest against the broader commodification of creative expertise in AI development…strategically framed to highlight OpenAI's alleged disregard for the economic value of artistic labor, echoing sentiments of discontent already prevalent in the AI ethics discourse”
www.forbes.com/sites/moinro...
www.forbes.com/sites/moinro...

OpenAI’s Sora Tool Leaked By Group Of Aggrieved Early Testers
At the heart of the controversy is a multifaceted conflict involving technological advancement, ethical concerns and artistic advocacy.
www.forbes.com
November 27, 2024 at 8:00 AM
“a protest against the broader commodification of creative expertise in AI development…strategically framed to highlight OpenAI's alleged disregard for the economic value of artistic labor, echoing sentiments of discontent already prevalent in the AI ethics discourse”
www.forbes.com/sites/moinro...
www.forbes.com/sites/moinro...
Hello!
I'm Giuseppe, currently working at AMD on open-source ML quantization.
If that's something you're interested in, check out: github.com/Xilinx/brevi...
We support all the fanciest SOTA quantization algorithm, with a focus on modularity and composability.
I'm Giuseppe, currently working at AMD on open-source ML quantization.
If that's something you're interested in, check out: github.com/Xilinx/brevi...
We support all the fanciest SOTA quantization algorithm, with a focus on modularity and composability.
GitHub - Xilinx/brevitas: Brevitas: neural network quantization in PyTorch
Brevitas: neural network quantization in PyTorch. Contribute to Xilinx/brevitas development by creating an account on GitHub.
github.com
November 24, 2024 at 12:46 PM
Hello!
I'm Giuseppe, currently working at AMD on open-source ML quantization.
If that's something you're interested in, check out: github.com/Xilinx/brevi...
We support all the fanciest SOTA quantization algorithm, with a focus on modularity and composability.
I'm Giuseppe, currently working at AMD on open-source ML quantization.
If that's something you're interested in, check out: github.com/Xilinx/brevi...
We support all the fanciest SOTA quantization algorithm, with a focus on modularity and composability.