



Craig Sherstan
@craigsherstan.bsky.social
AI Research Scientist - Reinforcement Learning.
Tokyo based.
Tokyo based.
My new paper with Michel Ma (www.linkedin.com/in/michel-ma/) is up on arXiv: arxiv.org/abs/2511.02094
We used an LLM to generate reward functions for RL trained racing agents in Gran Turismo and an VLM to evaluate their performance.
See, now I'm a cool LLM researcher :)
#LLM #RL #GranTurismo
We used an LLM to generate reward functions for RL trained racing agents in Gran Turismo and an VLM to evaluate their performance.
See, now I'm a cool LLM researcher :)
#LLM #RL #GranTurismo

Automated Reward Design for Gran Turismo
When designing reinforcement learning (RL) agents, a designer communicates the desired agent behavior through the definition of reward functions - numerical feedback given to the agent as reward or pu...
arxiv.org
November 9, 2025 at 2:52 AM
My new paper with Michel Ma (www.linkedin.com/in/michel-ma/) is up on arXiv: arxiv.org/abs/2511.02094
We used an LLM to generate reward functions for RL trained racing agents in Gran Turismo and an VLM to evaluate their performance.
See, now I'm a cool LLM researcher :)
#LLM #RL #GranTurismo
We used an LLM to generate reward functions for RL trained racing agents in Gran Turismo and an VLM to evaluate their performance.
See, now I'm a cool LLM researcher :)
#LLM #RL #GranTurismo
Tiny Recursive Model (TRM): 7M parameter LLM from Samsung with really performance similar to much larger models. The trick is to use recursive reasoning in the inference itself -> a tiny 2 layer model is called repeatedly.
arxiv.org/html/2510.04...
arxiv.org/html/2510.04...
Less is More: Recursive Reasoning with Tiny Networks
arxiv.org
October 30, 2025 at 12:51 PM
Tiny Recursive Model (TRM): 7M parameter LLM from Samsung with really performance similar to much larger models. The trick is to use recursive reasoning in the inference itself -> a tiny 2 layer model is called repeatedly.
arxiv.org/html/2510.04...
arxiv.org/html/2510.04...
arxiv.org/abs/2510.18212
> defining AGI as matching the cognitive versatility and proficiency of a well-educated adult.
... so if a human isn't a well-educated adult they don't have general intelligence?
> defining AGI as matching the cognitive versatility and proficiency of a well-educated adult.
... so if a human isn't a well-educated adult they don't have general intelligence?
A Definition of AGI
The lack of a concrete definition for Artificial General Intelligence (AGI) obscures the gap between today's specialized AI and human-level cognition. This paper introduces a quantifiable framework to...
arxiv.org
October 27, 2025 at 11:20 AM
arxiv.org/abs/2510.18212
> defining AGI as matching the cognitive versatility and proficiency of a well-educated adult.
... so if a human isn't a well-educated adult they don't have general intelligence?
> defining AGI as matching the cognitive versatility and proficiency of a well-educated adult.
... so if a human isn't a well-educated adult they don't have general intelligence?
Reposted by Craig Sherstan

This paper has now been accepted @neuripsconf.bsky.social !
Huge congratulations, Hon Tik (Rick) Tse and Siddarth Chandrasekar.
Huge congratulations, Hon Tik (Rick) Tse and Siddarth Chandrasekar.
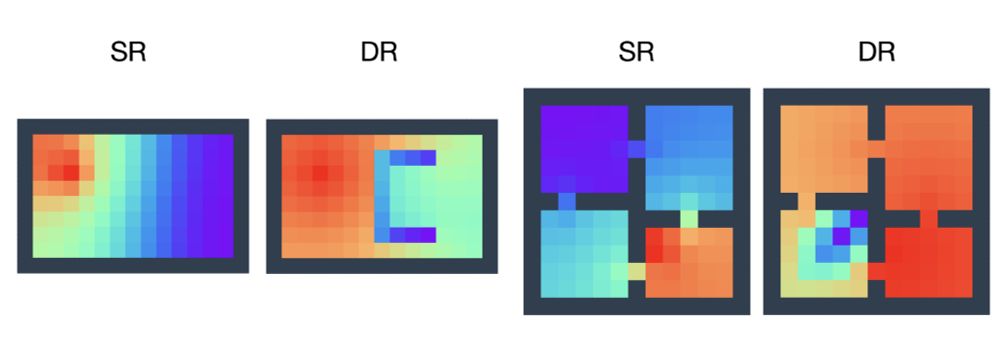
📢 I'm happy to share the preprint: _Reward-Aware Proto-Representations in Reinforcement Learning_ ‼️
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
September 18, 2025 at 10:04 PM
This paper has now been accepted @neuripsconf.bsky.social !
Huge congratulations, Hon Tik (Rick) Tse and Siddarth Chandrasekar.
Huge congratulations, Hon Tik (Rick) Tse and Siddarth Chandrasekar.
Really cool opening at DeepMind right now for someone to explore "what comes after AGI" (closes Friday Sept 26, 2025):
job-boards.greenhouse.io/deepmind/job...
job-boards.greenhouse.io/deepmind/job...
Research Scientist, Post-AGI Research
London, UK
job-boards.greenhouse.io
September 22, 2025 at 12:40 PM
Really cool opening at DeepMind right now for someone to explore "what comes after AGI" (closes Friday Sept 26, 2025):
job-boards.greenhouse.io/deepmind/job...
job-boards.greenhouse.io/deepmind/job...
Reposted by Craig Sherstan

Staff level link:
sonyglobal.wd1.myworkdayjobs.com/en-US/SonyGl...
sonyglobal.wd1.myworkdayjobs.com/en-US/SonyGl...
September 9, 2025 at 10:38 PM
Staff level link:
sonyglobal.wd1.myworkdayjobs.com/en-US/SonyGl...
sonyglobal.wd1.myworkdayjobs.com/en-US/SonyGl...
Reposted by Craig Sherstan
Sony AI is hiring game integration engineers!
We do awesome RL applications to modern video games. If that excites you, check out the posting!
We have positions for senior and staff level developers. Senior dev link (staff level link next in 🧵):
sonyglobal.wd1.myworkdayjobs.com/en-US/SonyGl...
We do awesome RL applications to modern video games. If that excites you, check out the posting!
We have positions for senior and staff level developers. Senior dev link (staff level link next in 🧵):
sonyglobal.wd1.myworkdayjobs.com/en-US/SonyGl...

Senior AI Integration Engineer for Game AI
Sony AI America, a branch of Sony AI, is a remotely distributed organization spread across the U.S. and Canada. Sony AI is Sony’s new research organization pursuing the mission to use AI to unleash hu...
sonyglobal.wd1.myworkdayjobs.com
September 9, 2025 at 10:37 PM
Sony AI is hiring game integration engineers!
We do awesome RL applications to modern video games. If that excites you, check out the posting!
We have positions for senior and staff level developers. Senior dev link (staff level link next in 🧵):
sonyglobal.wd1.myworkdayjobs.com/en-US/SonyGl...
We do awesome RL applications to modern video games. If that excites you, check out the posting!
We have positions for senior and staff level developers. Senior dev link (staff level link next in 🧵):
sonyglobal.wd1.myworkdayjobs.com/en-US/SonyGl...
Reposted by Craig Sherstan
The Sony AI Game AI team has reinforcement learning internships opens for 2026!
It is remote for people in the US & Canada, mixed remote/onsite in Europe (onsite in Zurich), and onsite in Tokyo.
If you want to work on RL with cool applications, sign up!
ai.sony/joinus/job-r...
It is remote for people in the US & Canada, mixed remote/onsite in Europe (onsite in Zurich), and onsite in Tokyo.
If you want to work on RL with cool applications, sign up!
ai.sony/joinus/job-r...

Reinforcement Learning Research Intern 2026 for Game AI – Sony AI
ai.sony
August 28, 2025 at 4:45 PM
The Sony AI Game AI team has reinforcement learning internships opens for 2026!
It is remote for people in the US & Canada, mixed remote/onsite in Europe (onsite in Zurich), and onsite in Tokyo.
If you want to work on RL with cool applications, sign up!
ai.sony/joinus/job-r...
It is remote for people in the US & Canada, mixed remote/onsite in Europe (onsite in Zurich), and onsite in Tokyo.
If you want to work on RL with cool applications, sign up!
ai.sony/joinus/job-r...
timed coding tests -> stress -> fight or flight -> loss of fine motor control -> ca n'ptt typp
September 3, 2025 at 3:29 AM
timed coding tests -> stress -> fight or flight -> loss of fine motor control -> ca n'ptt typp
Monday's talk "Two Tales of Reward Design: GT Sophy and Factored Value Functions" is online: youtu.be/PrsKX5ZWt_4
#RL #GranTurismo #GTSophy
#RL #GranTurismo #GTSophy

Two Tales of Reward Design: GT Sophy and Factored Value Functions
YouTube video by Craig Sherstan
youtu.be
August 28, 2025 at 1:01 PM
Monday's talk "Two Tales of Reward Design: GT Sophy and Factored Value Functions" is online: youtu.be/PrsKX5ZWt_4
#RL #GranTurismo #GTSophy
#RL #GranTurismo #GTSophy
Thanks to @marloscmachado.bsky.social for the invite to speak at the University of Alberta today. Hopefully someone remembers my main point: Reward design is really important. :)
August 25, 2025 at 8:45 PM
Thanks to @marloscmachado.bsky.social for the invite to speak at the University of Alberta today. Hopefully someone remembers my main point: Reward design is really important. :)
Reposted by Craig Sherstan
"A scientist believes..." isn't noteworthy unless it can be followed by "because science shows..."
August 25, 2025 at 1:55 PM
"A scientist believes..." isn't noteworthy unless it can be followed by "because science shows..."
I just came across a technical article written by *Dr.* So-and-so. Seeing Dr. made me more impressed and then I remembered "I'm a Dr. too". Inbuilt biases :P I'm definitely going to start using my Dr. title.
July 31, 2025 at 5:55 AM
I just came across a technical article written by *Dr.* So-and-so. Seeing Dr. made me more impressed and then I remembered "I'm a Dr. too". Inbuilt biases :P I'm definitely going to start using my Dr. title.
Learning to Reason without External Rewards arxiv.org/pdf/2505.19590
LLM finetuning is done ONLY using internal reward (model confidence) with no external grounding reward.
That means the LLM had to already know how to solve the problems.
LLM finetuning is done ONLY using internal reward (model confidence) with no external grounding reward.
That means the LLM had to already know how to solve the problems.
arxiv.org
July 13, 2025 at 10:35 AM
Learning to Reason without External Rewards arxiv.org/pdf/2505.19590
LLM finetuning is done ONLY using internal reward (model confidence) with no external grounding reward.
That means the LLM had to already know how to solve the problems.
LLM finetuning is done ONLY using internal reward (model confidence) with no external grounding reward.
That means the LLM had to already know how to solve the problems.
Sometimes I imagine a world where all the friends that I'm trying to coordinate use the same messaging app. One can dream...
July 11, 2025 at 12:14 PM
Sometimes I imagine a world where all the friends that I'm trying to coordinate use the same messaging app. One can dream...
I was playing with a couple of emotion detection models today.
Apparently my resting face is one of: disgust, anger, sad and my happy face is contempt :P
Apparently my resting face is one of: disgust, anger, sad and my happy face is contempt :P
May 3, 2025 at 3:40 AM
I was playing with a couple of emotion detection models today.
Apparently my resting face is one of: disgust, anger, sad and my happy face is contempt :P
Apparently my resting face is one of: disgust, anger, sad and my happy face is contempt :P
Cortical Labs combines human neurons with silicon computing for a cool #cyborg computer!!! And you can buy one, or use their cloud service.
corticallabs.com
corticallabs.com

Cortical Labs
We've combined lab-grown neurons with silicon chips and made it available to anyone, for first time ever.
corticallabs.com
March 7, 2025 at 12:24 AM
Cortical Labs combines human neurons with silicon computing for a cool #cyborg computer!!! And you can buy one, or use their cloud service.
corticallabs.com
corticallabs.com
Reposted by Craig Sherstan
Let's go! Really psyched to have Barto and Sutton win the Turing award for Reinforcement Learning! Their work shaped my career in such profound ways.
www.nytimes.com/2025/03/05/t...
www.nytimes.com/2025/03/05/t...

Turing Award Goes to A.I. Pioneers Andrew Barto and Richard Sutton
Andrew Barto and Richard Sutton developed reinforcement learning, a technique vital to chatbots like ChatGPT.
www.nytimes.com
March 5, 2025 at 2:27 PM
Let's go! Really psyched to have Barto and Sutton win the Turing award for Reinforcement Learning! Their work shaped my career in such profound ways.
www.nytimes.com/2025/03/05/t...
www.nytimes.com/2025/03/05/t...
doi.org/10.48550/arX...
Really cool approach: agentic LLM generates its own actions as python functions. However, this is NOT doing RL - there is no reward over which the system optimizes. #rl #llm
Really cool approach: agentic LLM generates its own actions as python functions. However, this is NOT doing RL - there is no reward over which the system optimizes. #rl #llm
DynaSaur: Large Language Agents Beyond Predefined Actions
Existing LLM agent systems typically select actions from a fixed and predefined set at every step. While this approach is effective in closed, narrowly-scoped environments, we argue that it presents t...
doi.org
November 25, 2024 at 1:58 AM
doi.org/10.48550/arX...
Really cool approach: agentic LLM generates its own actions as python functions. However, this is NOT doing RL - there is no reward over which the system optimizes. #rl #llm
Really cool approach: agentic LLM generates its own actions as python functions. However, this is NOT doing RL - there is no reward over which the system optimizes. #rl #llm
I'm giving a keynote on building GT Sophy - our reinforcement learning based racing agent for Gran Turismo. Tuesday Nov 26, 2024 8:40 JST (online). Computers and Games Conference. #rl #granturismo #sonyai #gtsophy

November 25, 2024 at 12:43 AM
I'm giving a keynote on building GT Sophy - our reinforcement learning based racing agent for Gran Turismo. Tuesday Nov 26, 2024 8:40 JST (online). Computers and Games Conference. #rl #granturismo #sonyai #gtsophy